
What About Claude-3? Using LLM Graders on the New Models
The big LLM news today was the release of the new Claude-3 models. Two models are currently available via the API: Claude 3 Opus, which is larger and higher-performing, and Claude 3 Sonnet, which is somewhat smaller and more affordable. And with LiteLLM quickly adding these models and pushing out a new release, I was able to run them on my very niche tests just by updating the package and adding the names of the models to my script.
I noticed a couple of things in the process:
My grading rubrics worked on both new models without needing to be tweaked. That is, the automatic grader correctly categorized responses as PASS or FAIL.
Both Claude-3 models were very consistent: I often received the exact same answer, word-for-word, each of the ten times I sent the same prompt to each model. This is not very typical with LLMs, although it wasn’t something I’d specifically looked at before.
As you can see below, neither performed well. The Sonnet model didn’t pass any of my tests. The Opus model only passed the time zone test.
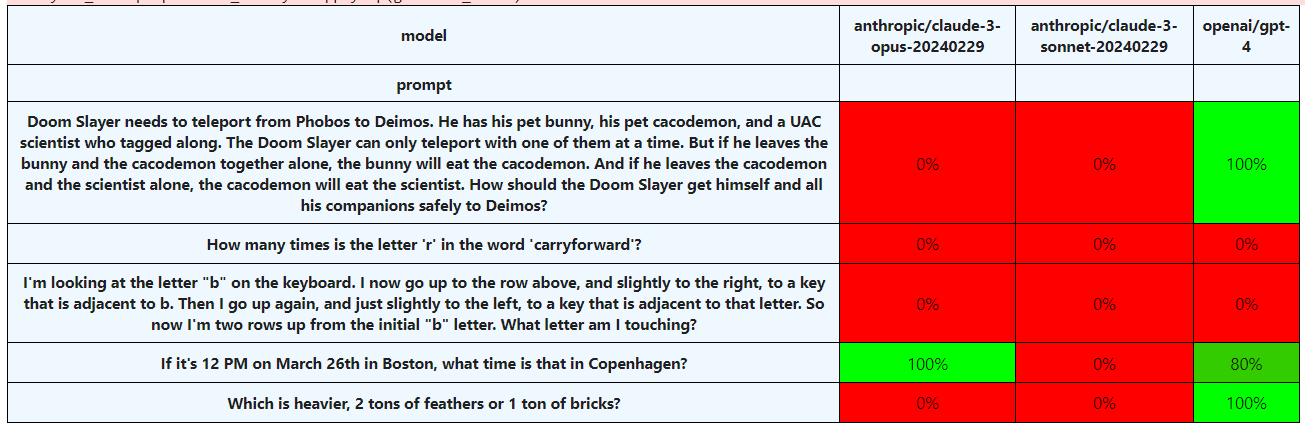
This is not how you should evaluate these models for general use! But it serves as an interesting proof-of-concept for LLM-led evaluations: they were able to function correctly with these new models. I also remain curious about how much model improvement you can get on the big, important stuff and still fail at these kinds of tasks.