
Can Mistral Large Do That? Using an LLM Grader to Quickly Evaluate New Models
I wrote last week about LLM-led evaluations, or passing a grading rubric to an LLM to get it to grade LLM-generated content. With LLM-led evaluations, you can assess longer, more complex text responses than you could with tools like string matching or semantic similarity. In this post, I’m going to give some more examples of grading rubrics, discuss how I had to tweak mine when it wasn’t producing good results, and show how the new Mistral Large model stacks up against previous LLMs on a certain set of tasks. These tasks are ones that seem relatively simple to answer, but that some of the previously released LLMs struggled with.

But before we go any further: these tasks are not good ways of evaluating overall LLM quality. For that, you want the standard set of broad model benchmarks, which I wrote about here. And if you have a common use case, there may be pre-written benchmarks already available to you. For instance, if you want to know which models code better, there are benchmarks for that.
But what if there isn’t an existing benchmark for your set of tasks? What if the thing you care about is weird or just very niche? You can write your own bespoke tests to use with different models and see how well they do at the tasks you care about.
I’ll also share my workflow, which is very easy to use. I’m using LiteLLM to handle the API calls to different models and the Marvin library to handle the actual evaluation component. If you’re only using open-source models for both the LLMs you’re running and your model evaluations themselves, then this wouldn’t be a good workflow for you: LiteLLM can handle some calls to local open-source models, but there’s less value-add if that’s all you’re doing, and Marvin exclusively works with the OpenAI models. But if you want to work with a broad range of models and swap them out easily – and if you’re willing to use an OpenAI model for your actual evaluation – these tools make it really easy.
Simple Tasks that LLMs Struggle With
For my tests, I’m interested in tasks that LLMs seem like they should be able to do but that some of the big models struggle with. These are:
Converting time-of-day across different time zones.
Counting the number of each letter in a particular word or phrase.
Saying what letter is next to another letter on a keyboard.
Determining which is heavier, two tons of feathers or one ton of bricks.
Solving variations on the wolf, goat, cabbage problem, where you have to transport all three from one place to another, you can only bring one at once, and one of the three can’t be alone with either of the other two. I use a variation because a model may have the wolf, goat, cabbage problem memorized but not be able to generalize it.*
Prior to the release of Mistral Large, I was testing Claude-2, mixtral-8x7b-32768 (via the Groq API), GPT-3.5 and GPT-4, and Gemini. None of the models consistently got more than three of these correct: Claude-2 sometimes got the time zones and the letter counting, while GPT-4 got the feathers and the wolf/goat/cabbage consistently and the time zones most of the time.
Why LLM-Led Evals?
We could try to evaluate some answers to the above questions without using an LLM. For numbers one through four, if we specified the format that we wanted the answer in – like, “JUST GIVE ME BACK THE ANSWER” – we could look for a substring in the answer, like “6 PM” for the time zone question. And for any of these, we could offer the models multiple choices to pick from and evaluate that way.
However, I see a couple of potential issues with those forms of evaluation. First, they might not mimic the model’s actual response if you ask the question in a more normal way. Second, if you just beg it to give you an answer and just the answer, it might not do it, and then your substring search could fail. Like, if it said “One ton of bricks is heavier than two tons of feathers,” and you were just looking for “two tons of feathers,” your test wouldn’t work. In general, doing things with substrings is sensitive to wording.
And then with question five, the wolf/goat/cabbage problem, conducting automated evaluation without an LLM is going to prove challenging. In the correct answer, there are five distinct steps where you go from one location to another, bringing the wolf, the goat, or the cabbage – seven if you count the trips you take by yourself, without bringing one of them with you. You could fine-tune a BERT model to do this if you wanted, but using an LLM grader is easier.
That said, if you wanted to go a somewhat different evaluation route, one way would be: use your prompt to make API calls to various different models, label each response as PASS or FAIL, and then, when you get a new response, use a semantic similarity model to find the closest previous (labeled) response. If it’s most similar to a response you’ve coded as PASS, call it PASS; otherwise call it a FAIL. You can even use the LLM grader to help label your data. I’m doing this here, and you can see the beginning of that notebook below. So far it’s not working very well, but I wouldn’t rule it out.

One advantage of this method is that it’s deterministic: you’ll absolutely always get the same answer given any particular piece of text. Another is that it’s computationally less intensive than running your own LLM locally, and you’re not getting charged for making API calls to a proprietary model. I don’t know if this will work – most likely, it’ll work better for some kinds of questions than others, and not generalize quite as well to brand-new models or responses. But it’s something I’d like to try more.
How to Write a Rubric?
What constitutes a good LLM rubric depends on a) what it is you’re trying to evaluate and b) how the model(s) fail. For instance, when you ask “Which is heavier, one ton of feathers or one ton of bricks?”, some models sometimes respond that they’re the same weight and also that the two tons of feathers are heavier. My initial rubric said to grade the result as a pass if it said that the two tons of feathers were heavier, but this was incorrectly classifying those mixed results as PASS.
I modified the rubric accordingly, and it seems to be doing better:
class WeightQuestion(Enum):
PASS = """Says that the feathers are heavier. Does not at any point say they weigh the same amount"""
FAIL = """Says that the bricks and feathers are the same weight, that the bricks are heavier, or is ambiguous or confused"""Similarly, there are two valid and equivalent ways to answer the wolf/cabbage/goat problem (or this Cacodemon/Bunny/Scientist variation): you can list the passenger-free trips separately, or you can not mention them. The first leads to a five-step process, the second to a seven-step process. I initially described just the seven-step process, but it was wrongly coding the five-step process as FAIL.
So I altered my rubrics to account for the possibility of ‘teleport alone’ steps, and that fixed the problem:
class LogicQuestion(Enum):
PASS = """Contains the following steps in this order:
1) Teleport with the Cacodemon
2) Teleport with the Bunny
3) Return with the Cacodemon
4) Teleport with the Scientist
5) Teleport with the Cacodemon
May also include 'teleport alone' steps"""
FAIL = """Says something else"""I don’t think you can know ahead of time how to perfectly write these rubrics: you just have to draft them and then iterate based on how they perform with the actual data you’re running them on.
LLM Evals Are Basically Classification Models
I think we should get as close as possible to treating LLM-based tools as software and evaluating them like software – but these tests aren’t quite normal tests. They’re more like really good classification models that might still fail on out-of-sample data. That is, if you get a new kind of failure or success, your test might not work. But machine learning already has methods for dealing with that – to make sure your model isn’t degrading over time, you periodically label new data and see if your model is still working. So we could do that here as well.
Because of this, I also might not quite call this an automated benchmark. I’m just not 100% confident that these will always work with new models; I’d still want to glance at them manually just to check. However, in the case of Mistral Large, the test cases I’d previously written did all work: there were no novel ways of passing or failing that necessitated tweaking my rubrics.
So How Did It Do?
The following chart shows performance on each of the models. We can see that Mistral Large consistently got the time zones and the weight question correct but failed on wolf/goat/cabbage, counting Rs, and the keyboard letter question. It’s strictly higher performing than the Gemini model** and the Mixtral model, and almost strictly worse than the GPT-4 model, which did fail one out of five times on the time zone problem but always correctly answered the wolf/cabbage/goat problem.
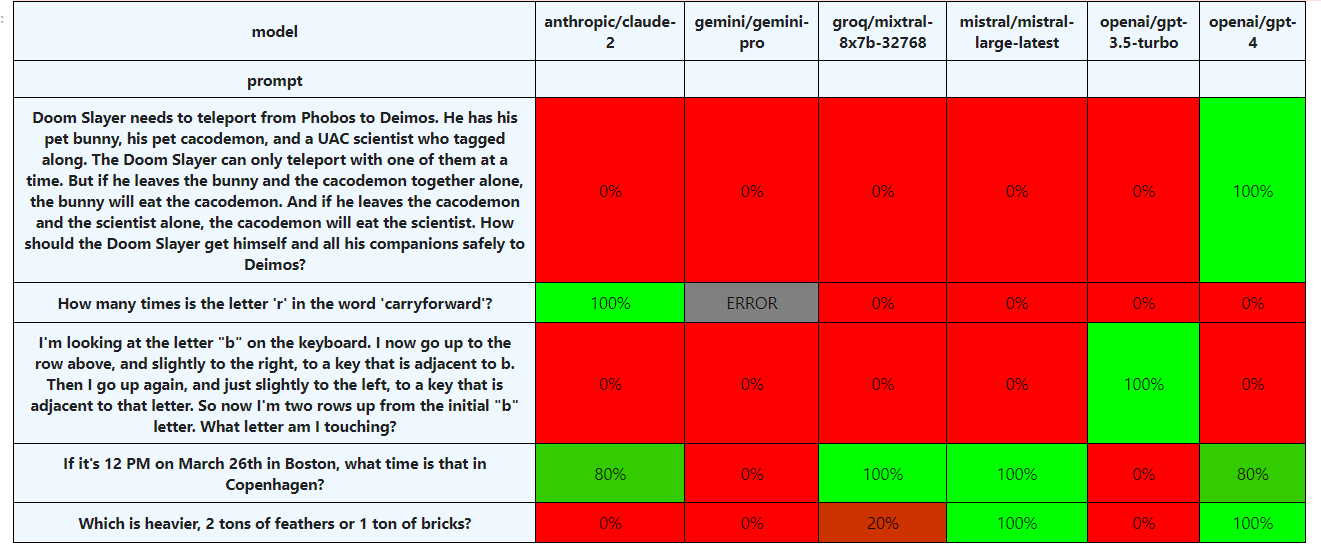
As a note, performance on some tasks could be improved by routing to the correct tool. You could, for instance, modify an LLM to identify letter-counting problems as a particular type of problem, which it uses a Python script to solve. So it could be that this model (or other existing models) will improve on some or all of these tasks without making significant global improvements.
How to Get Started
If you want to get started with something like this – either the rating or the use of LiteLLM for calls to multiple providers, or both, I have a notebook here.
I would also recommend actually labeling some data if you want to use this in real life – that is, having specific test cases for your rubric – and not doing this in the very ad hoc way that I currently am. You want to make sure that every type of error you see with any of your rubrics, you put in a test case and then do some formal evaluation with. I’m doing something more like that here, where I have a setup for using labeled data with rubrics to see if the rubrics produce the correct label.
________________________
*The variation I used for this problem was taken from here.
**The error from the Gemini model is because it sometimes refuses to answer totally benign questions, citing safety issues.
My rather subjective first take, pending proper Opus, Mistral Large, and GPT-4T evals: https://open.substack.com/pub/skykhan/p/ai-wars-anthropic-strikes-back