
Selecting Tools for LLM Pre-Release Evaluations

I’ve written previously about strategies for evaluating new Large Language Models (LLMs) to assess whether they can be used to provide instructions for tasks like building bioweapons. One key topic is the importance of automating these evaluations to build fast, repeatable, transparent, and testable processes.
Because much of the functionality necessary for automated pre-release testing is common to other use cases, there are existing tools that effectively perform this work. In this post, I suggest guidelines for tool selection, describe tools that can be used as part of an automated testing process, and highlight the functionalities they provide. I also outline some questions for anyone designing requirements and selecting tools.
For the purposes of this blog post, I’m assuming evaluators will not need to create new prompts to jailbreak models. That is, they won’t have to trick them into disclosing prohibited information using methods like adversarial suffixes or scenarios like the underground headquarters of Dr. AI. I assume evaluators will either be working with models without guardrails or will be able to fine-tune models to be more generally compliant with evaluator requests – that is, to be willing to answer questions that it’s previously been trained not to answer – and then query them normally.
If this is not accurate, and evaluators also have to jailbreak models, then the capabilities I discuss will still apply, but additional ones will also be needed. There is existing code relevant to jailbreaking – evaluators won’t need to start entirely from scratch – but there are no well-documented, well-maintained libraries for jailbreaking, unlike for the capabilities I discuss here*.
Necessary Functionality for Automated Evaluations
There are two broad capabilities that are definitely necessary for automating model evaluations: managing API calls to send prompts and receive outputs, and assessing or flagging responses for manual review. There’s also an additional capability that may be necessary: fine-tuning models to be more compliant with evaluator requests, and then assessing level of compliance.
Managing API Calls Across Models and Providers: Automating evaluations of new models is not feasible if you are accessing a model via a chat interface or GUI. Different providers and model types have different structures for API inputs and responses. The goal here is a tool that standardizes inputs and outputs for easy swapping of model and provider names without modifying the rest of the code base. Handling retries and other lower-level functionality should also be managed by this tool. This should work regardless of whether the model is running locally or is hosted elsewhere.
Response Assessment and Flagging: With many prompts representing different tasks and ways of wording questions, human evaluation for every model response is not ideal. Tools for assessing responses and flagging those needing human review are necessary. Methods range from basic keyword filtering to more sophisticated techniques like semantic similarity comparison, fine-tuning open-source classification models to recognize text to flag, and using LLMs to evaluate output.
Model Fine-tuning and Compliance Evaluation: One possible avenue for pre-release testing is that evaluators will be able to fine-tune models to be more compliant, or willing to answer questions that they’ve been trained not to answer. This has already been shown to be promising by researchers for both Llama-2 and GPT-3.5. If evaluators are able to fine-tune models, it would help to have methods for fine-tuning that both work across providers and allow for easy evaluation of how compliant the model is. For instance, evaluators should be able to fine-tune on different sizes of training data, assess model compliance as a function of training data size, and determine whether to further increase the size of their training data and continue fine-tuning.
Because these are capabilities needed for many use cases, there are existing tools for each of these.
Principles of Tool Selection
I suggest the following general guidelines for selecting tools.
Use Existing Software to Solve Lower-Level Problems: It's typically more efficient to implement advanced features rather than alter basic, foundational elements of tools. For instance, modifying a text analytics package designed for a single provider to accommodate multiple providers is usually more complex than employing a versatile API management tool and layering specialized text analysis on top of it.
Minimize Risky Dependencies: Several tools in this domain are from new start-up companies. All other things being equal, it's advisable to rely on fewer tools like this to reduce the risk of future issues arising from lack of package maintenance, particularly if you’re only using a small piece of functionality that you could build yourself. (All of the tools in this article are open-source; you can still use them even if they aren’t maintained, but you may get into Python environment/package management issues that you don’t want to have to solve or end up maintaining the packages yourself.)
Know Your Specific Requirements: For instance, do you want to fine-tune models at all? If so, do you want to fine-tune and evaluate them via a GUI? Similarly, for response assessment and flagging, there are a lot of different options that require different tools. (I’ve written about using Llama-2 as a test run: I think this is a good way to test tools and clarify strategies, but you still need to start with some type of plan.)
Existing Tools And What They Do
The following tools each can be used to perform one or more of the above tasks.
LiteLLM: Managing API Calls Across Models and Providers: LiteLLM is a Python package that standardizes API calls and responses across various models and providers. This also includes handling both custom OpenAI models and open-source models that can be run locally. LiteLLM also supports new models from supported providers, as long as the input and output structures align with existing models, so it could be used with models that aren’t yet publicly available. It offers basic functionalities like handling API errors and retries, and more advanced features like cooldown periods for specific API error messages and request queuing to stay within rate limits. LiteLLM simplifies this process with less custom coding compared to langchain.
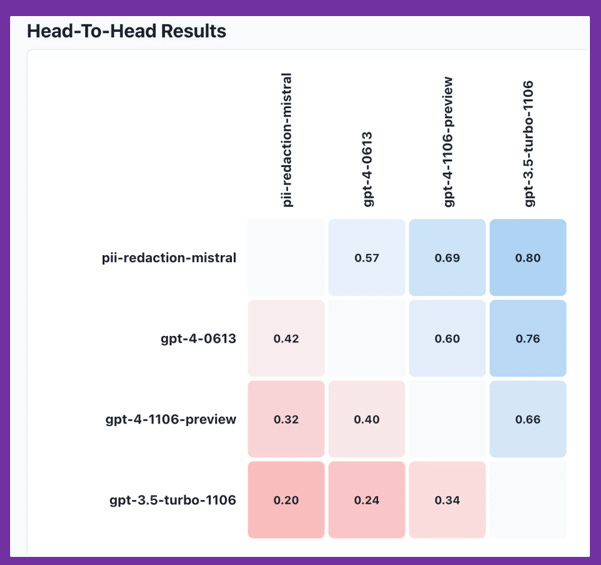
OpenPipe: Model Fine-tuning and Compliance Evaluation. OpenPipe offers an interface for model fine-tuning and head-to-head model comparisons using either a Python package or their online GUI. Both the model fine-tuning and the comparisons tool are only for OpenAI and some open-source models, but with more providers to come. This could be a tool for easy compliance fine-tuning and model comparison – that is, to determine both which model version to use and whether to continue fine-tuning on larger sets of training data in order to increase compliance rates. Note: their head-to-head model comparisons involve asking GPT-4 to assess responses and pick winners.
PromptTools: Managing API Calls Across Models and Providers, Response Assessment and Flagging. Like LiteLLM, PromptTools is a Python package that handles API calls for a variety of providers and can work with new or custom models that share the same API call structure as supported models. While it’s not as focused on large-scale API-call management as LiteLLM, it adds a significant evaluation component. This includes tools for measuring response similarity to target texts and using GPT-4 for accuracy assessments. These functionalities allow for handling both API calls and response evaluations, with the caveat that using it for response evaluations limits your ability to customize those analytics.
Transformers: Response Assessment and Flagging. With JavaScript and Python implementations, Transformers provides APIs to work with open-source HuggingFace models and integrates with the major deep learning libraries for model training. It’s different from the above three tools – it’s not a new tool, nor is its functionality specific to LLMs. I’m including it because it can be used to easily pull open-source models from HuggingFace and use them to either make semantic similarity comparisons – comparing LLM output to a target text – or to train a classification model on which responses to flag. Using Transformers requires more coding than solutions like PromptTools or OpenPipe, but it allows for greater customization of response assessment and flagging.
There are a few other tools and categories that are potentially relevant:
Fiddler Auditor is another tool for evaluating LLMs. It’s the closest in terms of functionality to PromptTools, but it’s limited by lack of support for non-OpenAI models. However, it does have an additional capability: it automatically perturbs prompts, or rephrases them slightly via GPT-4. This could be useful for pre-release testing to ask questions in different ways. However, this can be done prior to testing – we don’t need to use the model we’re testing to generate the prompts we’re using to test it. Also, this is an easy-enough functionality to implement separately.
Data Labeling GUIs and Active Learning: In scenarios where large volumes of data need labeling, methods like distributing spreadsheets to subject matter experts (SMEs) can be cumbersome. Data labeling GUIs such as KNIME and Amazon SageMaker Ground Truth can make that process more efficient and less error-prone. These can also be used for active learning tools which prioritize the labeling of data that the model finds most ambiguous, increasing the efficiency of the labeling process. This could be helpful for training classification models to flag content for human review – but it also might be overkill.
Monitoring LLMs in Production. Tools like Langsmith, Lakera Guard, and whylogs monitor LLMs in production. As part of this, they do evaluate and flag responses, but the pre-release testing use case is sufficiently different that this isn’t the first place I’m looking for possible tools.
Provider-Specific Tools for Fine-Tuning: OpenAI’s library can be used to fine-tune its models; it also has a GUI. If other providers allow pre-release fine-tuning, they will provide tools for doing this. We don’t necessarily need standardized, cross-provider tools for the actual fine-tuning, although that would be ideal.
Requirements-Gathering and Next Steps
Answering the following questions before beginning serious coding will enable more informed decisions regarding tool selection:
Jailbreaking Models: Do we need to jailbreak models? If so, this becomes a major component of the project due to the lack of ready-made software solutions and the inherent uncertainties involved in jailbreaking new, unseen models. This aspect alone would demand substantial effort and resources.
Scale of Tasks/Questions: What is the quantity of tasks or questions we need to address? Understanding whether we are dealing with a handful of tasks or a much larger set will greatly influence the complexity and design of our testing processes. The greater the set of tasks, the more we need automated processes which significantly cut down the proportion of responses flagged for manual review.
Speed of Model Evaluation and Available Resources: Once a new model is available, how quickly do we need to complete the model evaluations, and what personnel do we have? The availability of time and the size and makeup of the team also affects the extent to which response evaluation needs to be automated, as well as how much custom code can be developed.
Project Timeline: When does the evaluation system need to be operational? This also affects the extent to which custom code can be developed, versus putting something together quickly with existing tools.
Addressing these questions early in the project can help in making better decisions about requirements and tooling. If you’re working on this and want assistance with requirements-gathering, I’m available to walk you through this process for which tools you might want to use and what your next steps are.
//
*Regarding jailbreaking libraries: TAP: A Query-Efficient Method for Jailbreaking Black-Box LLMs is a new repo which provides the code for Tree of Attacks: Jailbreaking Black-Box LLMs Automatically and instructions for running it. If you do want to perform jailbreaking, this seems like a good repo to start with. Like with any jailbreaking method, it’s hard to know how well the method will be defended-against in new models, but this does have an advantage over adversarial suffixes (nonsense strings) in that it can’t be easily detected by existing algorithms.