
Making a Chatbot With Your Documents
I recently wrote/assembled some code to get a repo which does the following:
Downloads some code and documentation from a couple of existing GitHub repos using the GitHub API; saves these as .txt files.
Processes the files and stores them in a particular format called a vector database, which represents the content of these files as numerical vectors.
Creates an interface with an app called Gradio so that you can use GPT-4 in conjunction with the documents - basically, a chatbot which also has access to your documents.

Here are some questions that I’ve been thinking about a lot over the last few weeks as I work on this and related projects.
What does any of this mean?
Let’s say you have a document you want to ask ChatGPT about. You could paste that document into ChatGPT and ask a question, and it would use that document to answer. Building a chatbot with documents does the same thing – except it determines which documents are related to your question, and ‘pastes them in’ for you so ChatGPT can access them.
The user just sees a text box where they can put a prompt in, and then the output from ChatGPT – but in the background, when they ask a question, a data structure called a vector database (in this case, a vector database called Chroma) is being searched to find document chunks that are relevant to their prompt.
Can I see that in a diagram?
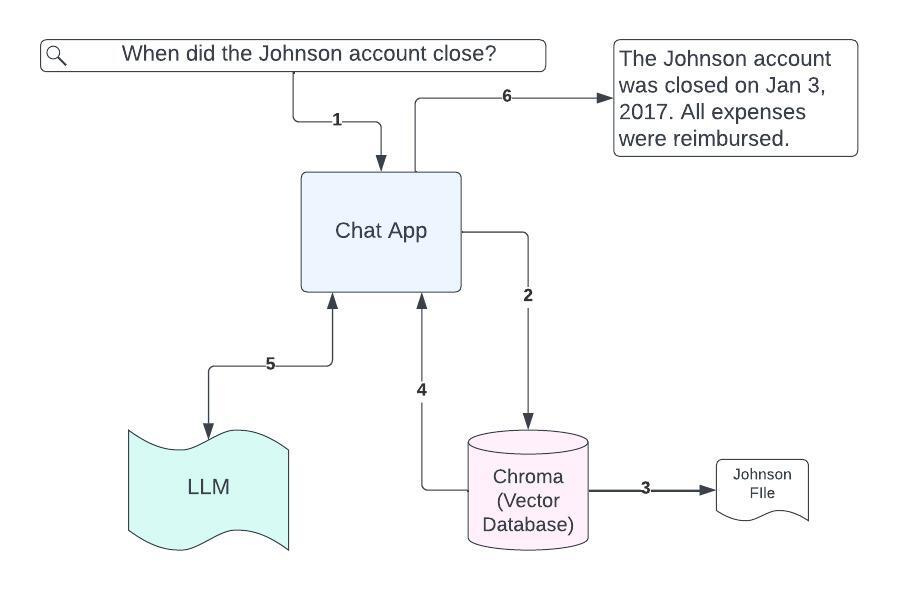
User enters question in the chat console
The application converts the question into an embedding and uses the embedding to search the vector database.
The vector database finds relevant document chunks.
The full text of those chunks is returned to the chat application.
The chat application sends a modified prompt to the LLM, including the full text of the found document chunks. ("Using the above document, answer the following question: When did the Johnson account close?")
The LLM response is returned to the user.
Why should I use this method instead of using ChatGPT directly without pasting in any text?
ChatGPT was trained on a particular set of data. If the documents you want to ask about aren’t in that data set, either because they weren’t on the internet in 2021 or just because they weren’t part of the training corpus, then ChatGPT isn’t going to know about them. To ask questions about those documents, you’re going to have to paste them in, either manually or programmatically. Even if they are part of that data, if you want to create a chatbot that’s extremely specific–such as where are the answers to all of the questions someone might ask in a particular set of documents–you also might want to do this.
Is this fine-tuning a model?
No! Fine-tuning or training refer to methods by which you change how the model works, what it ‘knows’, or what words it puts after what other words. We're not teaching anything to GPT-4 or updating its functionality; we're simply supplying it with text to use. It’s not learning anything to use next time you ask it something.
This is an important distinction for a few reasons. You can’t currently fine-tune GPT-3.5 or GPT-4, so if you want those models to answer questions about your specific documents, this is the only way to do it. Also, when fine-tuning models, your data has to be in a particular format: structured data that shows the model how to answer particular types of questions. Another challenge of fine-tuning is that it takes more training data to get models to change how they answer questions than it does to use this method.

Can I do this with open-source models?
Absolutely. In fact, you can think of this as a two-step process. First, you’re creating the “embeddings:” the vectors of numbers that represent your documents for storage and search in the vector database. This is a representation of your data that makes it easier for the vector database to quickly find which chunks of text are related to your question. Second, you’re using a text generation model, like GPT-4, where you’re sending the relevant document chunks in conjunction with your prompt, or question. OpenAI has both embeddings and models and there are also open source embeddings and text generation models. You can mix and match! If you do use OpenAI, you’ll be charged for both creating the embeddings and running the model. Pricing for both embeddings and ChatGPT are here.
What tools should I use for this?
There are a lot of programs out there with code which will try to read in your data, even if it’s coming from a variety of different document types (.pdfs, .docx, .txt, etc.), and then create a chatbot with them. But I think you should use the langchain library directly, and handle your own document ingestion yourself.
This is for a few reasons.
You’re going to have an easier time troubleshooting issues with a commonly-used library with a lot of documentation. Troubleshooting error messages from some random demo repo someone just made recently that no one’s using much is a problem you don’t have to solve. Solving document ingestion for all kinds of different documents is a pretty hard problem – documents can be weird for all kinds of reasons! But solving it for just your own documents is generally a much less difficult problem.
You can also get more customization if you code it yourself. For instance, I was using the GitHub API to pull a couple of different document types from GitHub and then doing a small amount of cleaning on them. If I were using someone else’s code for pulling documents from a website, I would not have been able to get the degree of specificity or cleaning that I needed. And once you have the .txt documents in a folder, processing them with langchain does not take much code.
Coding your own solution gives you access to the complete functionality of langchain, including using whatever model you want, as opposed to just what someone else’s library has implemented.
That said, if you’re an enterprise and you’re paying someone to ingest your documents and handle your weird edge cases, that’s a different use case.
Do I actually need ChatGPT if I’m pasting in the text with the answers, or can I use a lower-quality/smaller open source model?
You may not need ChatGPT-like performance. It depends on your use case. I’ve been playing with much smaller open-source LLMs using this method, and there’s definitely a performance-size relationship. The smaller, worse models are still smaller and worse, even if you feed them your documents. But I haven’t tried the really big open source models yet, so I don’t know how they perform on this type of task relative to the ChatGPT models.
What do I need to get started?
If you want to use GPT for either the embeddings or the model, you’ll need an OpenAI API key. If you want to go open-source, you won’t, but you’ll probably want cloud resources like those on SageMaker or Colab.
You can see my git repo here. It’s very bare-bones, particularly the Gradio app, but it does have the capability of saving out the embeddings so that you only do that step once, and then it looks for the database to run the chatbot on in subsequent runs.