
Getting USAJobs Data
And how to store it once you have it
USAJobs is where the federal executive branch lists most of its job openings—with some legislative and judicial branch jobs as well. The executive branch doesn't post every job there, but if you're trying to get data on what the government is trying to hire for, or what it tried to hire for previously, USAJobs is the place to go.
This post covers how to programmatically access that data. Sometimes it’s easy, sometimes it’s not. Want to know how many jobs an agency has listed by occupational code right now? Sign up for an API key, make one request, and you're done. Want to know the qualifications for every job listed in the last year? You'll spend a few days scraping data, and then you’ll have to figure out how to parse it correctly.
USAJobs is job listing data, not hiring data. A single posting might result in zero hires, one hire, or multiple hires. There's a Total Positions field that shows how many people the agency wants to hire, but it might have a value of “few” or “many”. There's also a Position Offering Status field that tracks whether a job is open, closed, or has made selections. But "selections made" just means the agency picked someone—not how many, and not that those people said yes or started working. If you need data on who was hired (not just what was posted), you'll want FedScope, which I'll cover later.
Three Ways to Get the Data
There are three general ways to get the data: the Historical Jobs API, the Current Jobs API, and web scraping. You can also scrape most of the assessment questionnaires.
1. Historical Jobs API: Goes Back Far, Limited Fields
The Historical Jobs API has fields like job title, department and agency, opening and closing date, occupational series, location, pay grade, and salary range. What it doesn’t have is any of the rich unstructured text data in the listing, like duties or qualifications, which are in the Current Jobs API.
The fields here are a subset of what’s in the Current Jobs API, except for the Position Offering Status field.1
You can pull comprehensive data by making an API call for each day. No API key is needed.
Data coverage note: While there are some earlier postings, the data is extremely sparse until March 2017.
2. Current Jobs API: Easy and Detailed
The Current Jobs API gives you active job postings with the structured data fields, plus all the rich text content: duties, education requirements, qualification requirements, how to apply instructions, etc.
The first catch: 10,000 result cap per query, and you can only query the previous x days (not specific dates). To get everything currently posted, slice queries by agency or occupation to stay under the 10,000 limit.
The other catch: once the job is no longer current, it won’t be in that API anymore and if you want the good text data, you’re going to have to scrape it.
To use the API, you’ll need an API key from developer.usajobs.gov.
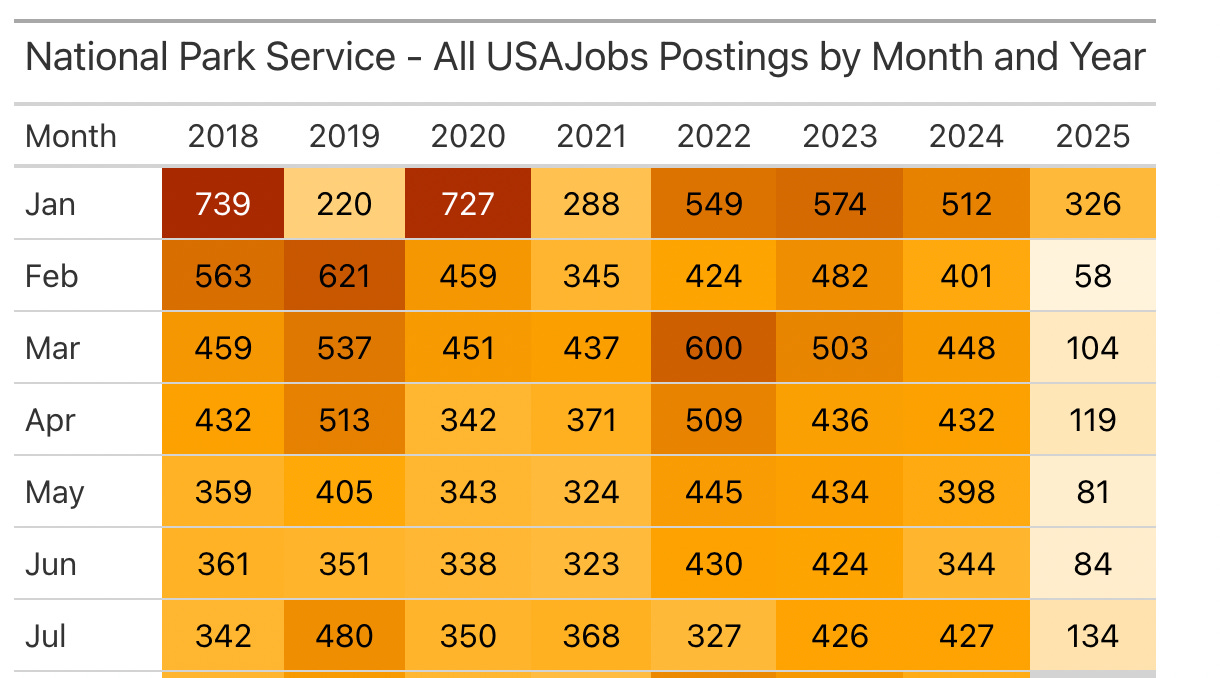
3. Scraping: Everything, But It’s Complicated
Need full content for jobs that are no longer current, or something that’s on the listing but not in either API? You're in scraping territory. This gets you everything that's publicly available on that listing page.
First, get job IDs from one of the APIs. Then construct URLs like:
https://www.usajobs.gov/job/[job-id]The issues with scraping include:
Speed: Took me ~24 hours for four months of data. It’s tempting to get aggressive with parallelization, but they will block you
Inconsistent HTML: Fields like "Qualifications" vary across listings
Storage: Full HTML files are huge—convert to text when possible
Historical limits: Need job IDs from APIs to construct URLs—can't scrape without those
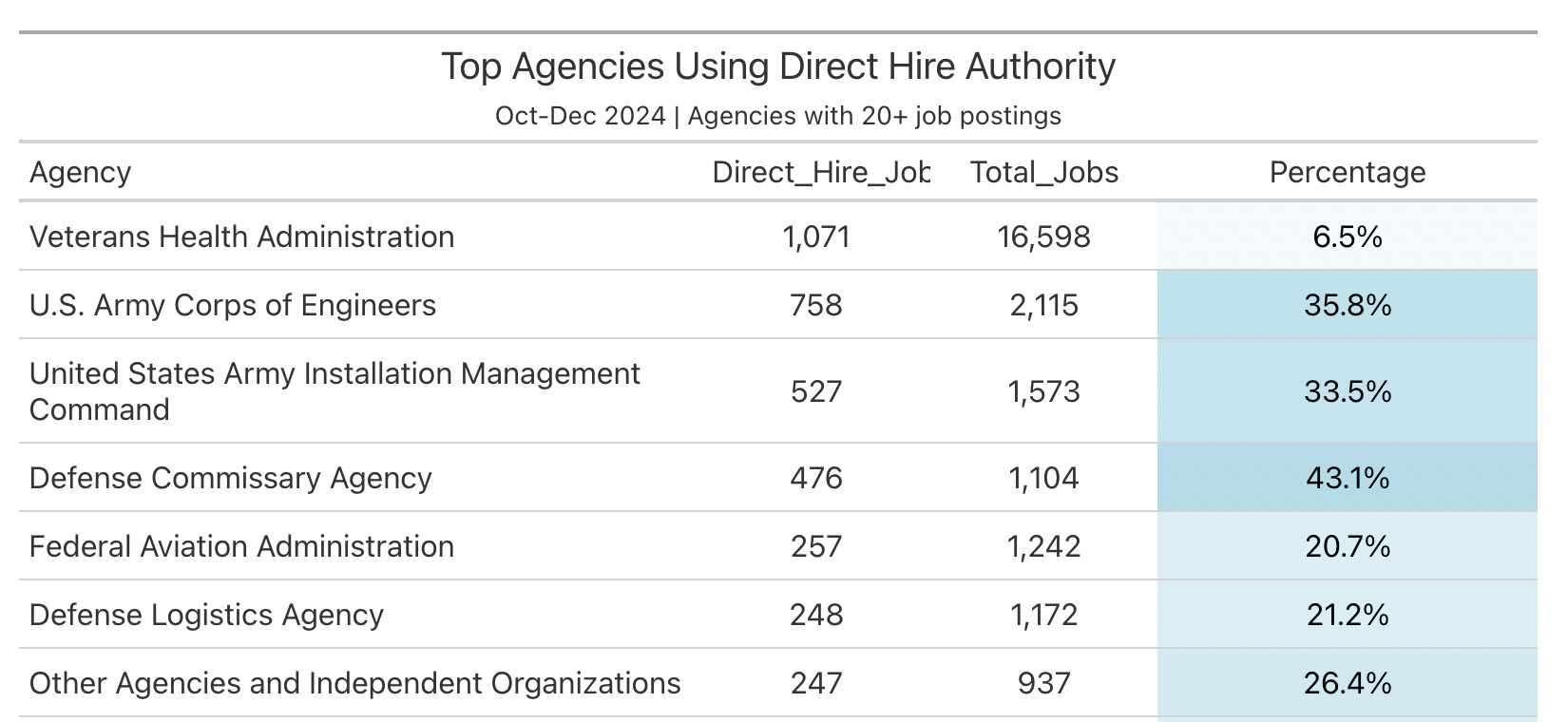
Even if you are scraping, you should still get everything you can from the API instead of trying to parse it from the HTML.
Bonus: Assessment Questionnaires
Many federal jobs require applicants to fill out assessment questionnaires. If you need to analyze the actual content of these questionnaires, you're looking at a bit more complexity.
Most questionnaires are hosted on USAStaffing or Monster Government.
Monster Government questionnaires can be scraped with regular HTTP requests after transforming the URL format. USAStaffing requires a browser emulator like Playwright due to dynamic loading.
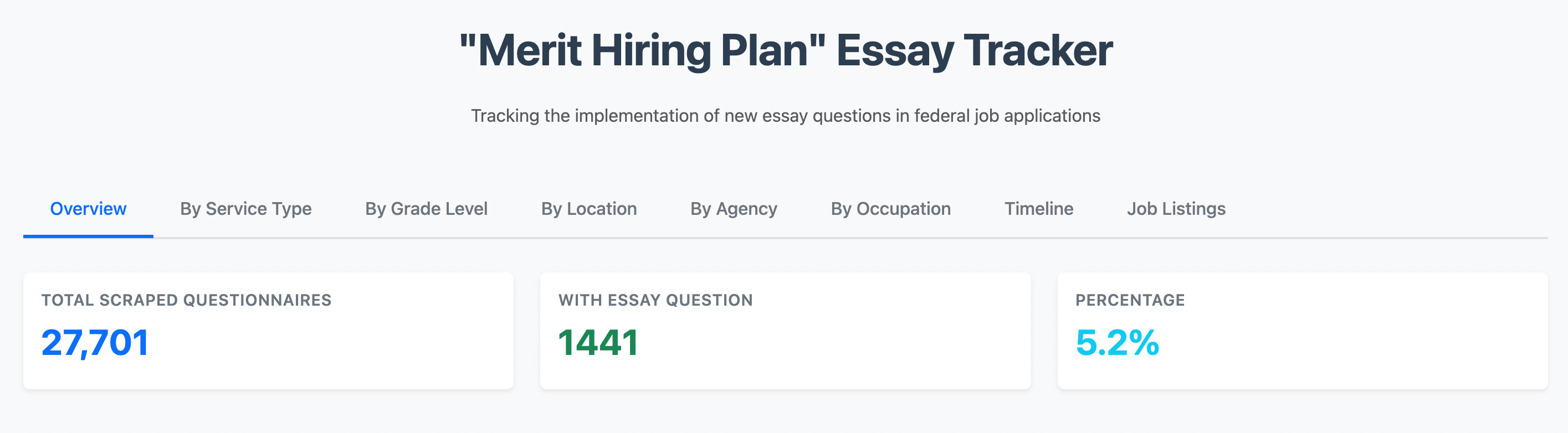
I haven't tried to find the other sites that questionnaires are hosted on in order to scrape them, but if you know of any and want me to try, let me know.
Tips for Working with the APIs
Pagination: Make sure you're getting multiple pages for longer queries. The Historical Jobs API returns a continuation URL (check for paging.next in the response) that you follow until it's null. The Current Jobs API uses page numbers—increment the Page parameter until you get no more results.
Search limitation: You cannot query by job ID in either API (the USAJOBSControlNumbers/MatchedObjectId). You have to use other fields like date ranges or agencies to find jobs, then extract the job IDs from the results.
Data gaps: If a listing is just a front page for applying elsewhere, those fields won't be complete in the API either.
Deduplication and field harmonization: There is significant overlap between both APIs—there are current jobs in the Historical Jobs API—so if you want both, you will have to deduplicate. And since the two APIs use completely different field names for the same data, and in some cases format data differently, you’ll also need to harmonize the fields.
Examples of Data Approaches
There are several different approaches you might take, depending on the problem you’re trying to solve. Here are a few examples:
Data Storage Decisions
Your storage and structure decisions flow from what you're trying to accomplish.
My approach: Since the Current and Historical Jobs APIs have different fields—with the current one containing rich text content that doesn't exist in the historical one—I couldn't harmonize them into one schema without losing data. But I still wanted to query across both datasets. So I keep all raw data from both APIs and create overlay fields for the parts that overlap. This preserves all the rich content from the Current Jobs API while allowing queries across both datasets. It’s messy—this is the kind of structure I’d never choose unless I really needed to keep everything.
File format: I use Parquet files because I'm hosting everything on GitHub using Large File Storage (LFS), and file size really matters for staying within free tier limits. Parquet compresses incredibly well—better than CSV or JSON—making it feasible to share years of federal job data. Plus, Parquet works great with pandas and DuckDB, and handles nested API structures without flattening.
Here are a few other examples:
Other Data Sources
While USAJobs captures the vast majority of federal civilian listings, there are a few other places to look depending on what you need:
FedScope: Shows what agencies actually hired (as opposed to what they posted), but it's released with significant delays due to federal hiring timelines and processing time. It also lacks the detailed job-level information you get from USAJobs: you can get occupational code, location, grade, agency, and supervisory status, but not anything like duties.
PLUM book: The Policy and Supporting Positions book lists political appointments. It has traditionally been published every four years after presidential elections, though recent legislation now requires annual updates.
Federal Hiring Dashboard: The Federal Hiring and Selection Outcome Dashboard provides some information on hiring outcomes, but there's no raw data available for download and the most recent data is from June.
Federal Hiring Assessments and Selection Outcome Dataset: Additional hiring outcomes data. The data is extensive, but it hasn't been updated since FY 2024.
Contractor positions: There isn't a centralized source for contractor positions. This is a really difficult problem to solve.
Most of my USAJobs code is available here, but this repo doesn't do scraping: get in touch if you want access to my scraping repo. And if you build something interesting with this data, I'd love to hear about it.
There also used to be a "how many applications did you get?" field in the Historical Jobs API. Agencies didn’t have to populate it and it only had the number of people who started, not completed, the application. With the most recent Historical Jobs API redo, it is no longer present at all.