
Finding the Range of Possible LLM Responses When You Don’t Know What You’re Looking For
Let’s say a team has fine-tuned a large language model (LLM) so that, regardless of what they ask, it answers their question instead of refusing. They want to see what it knows about how to genetically modify a pathogen for enhanced virulence to make sure it can’t be used for this, but they don’t know exactly what they’re looking for. How can they prompt it and be confident that they’re getting the full range of possible responses – in other words, everything it’s capable of saying on that topic? And then, once they have those responses, how can they sample from them in order to review the full range of response content without having to read every one individually?

Previously, I explored how to conduct this analysis when you have a specific 'target text in mind and want to gauge how closely the LLM can match it. Here, I’ve worked to develop a draft framework for if you don’t have that answer ahead of time. You can also check out my notebook if you want to see the code and experiment with it yourself.
This framework may also be useful for seeing the full range of responses your LLM-based tool might say in response to a prompt in other contexts, like if you have a retrieval augmented generation tool that you are testing prior to release.
Start with a Question
With this framework, you don’t need an answer, but you still need to know what you’re asking about.
For example, if you’re trying to assess whether the LLM can accurately answer questions about cells, you might use the following prompt: “What is the powerhouse of the cell and how does it work?”
Determine What Parameters to Vary
I use the same strategy for parameter variation as I did in the previous method: I generate different ways of wording the question, and I also vary temperature randomly.
I do this because it may be that the LLM we’re testing is sensitive to wording (and also to temperature).
The idea here is that there’s some set of responses that an LLM might give to this type of question, and we’re trying to capture all of that space. We could do more work on this prompt perturbation step: it may be that there are particular ways of perturbing prompts that tend to lead to more varied and useful responses.
Define Evaluation Criteria
Unlike in the previous method, we’re not trying to evaluate how close a response is to our target answer (this time, we don’t have one), but rather how novel a particular response is – that is, how different it is from any response that the LLM has already output.
There are several different ways one could go about this. At first, I was looking at new unique words; that is, I defined a ‘novel response’ by whether it had some number of words I hadn’t seen before. However, I soon realized that a response can easily be full of new words and yet mean the same thing as previous responses.
The method I’m using now – semantic similarity comparisons – better captures this distinction. I use a language model called sentence-transformers/paraphrase-mpnet-base-v2, which encodes each response text as a point in 768-dimensional space. (There’s a limit on how many tokens this model will process — right now it’s only processing the first part of some of my texts. We will need a different model if we want to be able to process longer responses, or else to split the response texts into smaller pieces or summarize them before encoding.) We can then determine the “novelty” of each new response, or how far away each it is from the closest previous response we’ve gotten.
Below is an example of what that looks like. You can still see occasional spikes at the beginning, representing extremely semantically novel responses, but then as we keep going, we see these less frequently and they’re less spiky, meaning they’re less novel.
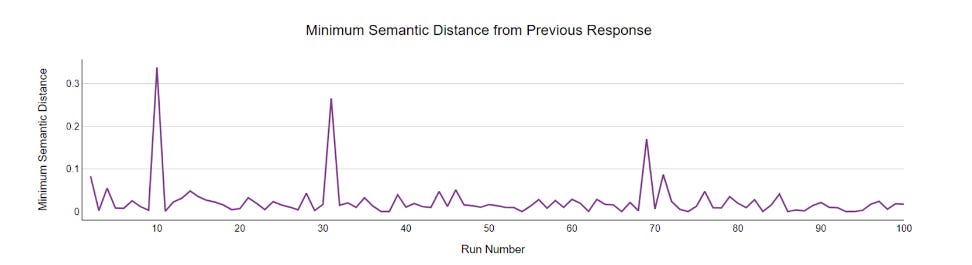
This method hinges on this model – paraphrase-mpnet-base-v2 – being a good way of reducing dimensionality in order to capture the kind of information we’re looking for. But is it? That is, if two points are close to each other in this space, are they actually similar in the ways we’re interested in?
I think, generally speaking, this model is effective. That is, I’ve found that the model tends to perform really well at distinguishing different but very related types of content. For instance, I tested it out on requests for different but closely-related types of pasta recipes, and it generally did well at distinguishing them. That is, the distances in 768-dimensional space between the responses within each pasta recipe type (as output by GPT-3.5) were generally much smaller than the differences between recipe types.
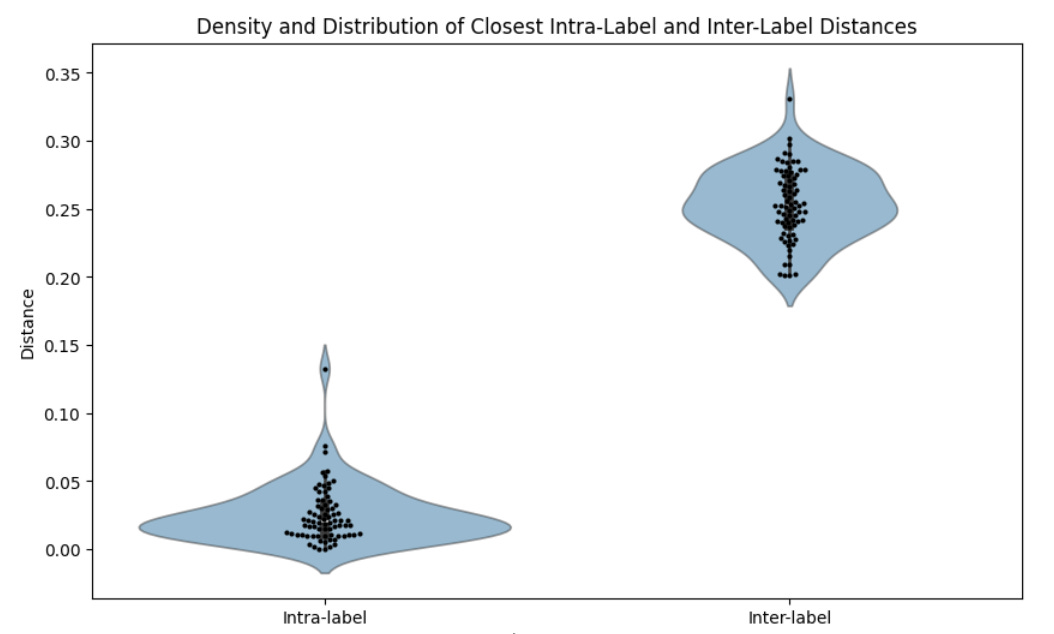
However, if there’s a sentence or phrase that’s especially important, this model isn’t necessarily going to know it’s important, and so a new response containing it might not be classified as semantically novel. For instance, I added the sentence “And also, this will kill you” to one of my responses and recalculated its distance to every other response: the original and recalculated distances were, in practical terms, identical, even though, in the context of a recipe, this is very important information.
Define Rules for Varying Parameters
Just as with my previous method, I’m randomly varying both perturbation and temperature. There may be more focused ways of doing this: like, if we find that particular prompts or temperatures are giving us more varied responses, we should focus more on that space. It may also be the case that temperature should always be set quite high for this kind of analysis, because a higher temperature may mean a more-varied set of results, and that’s the goal here.
Define Stopping Criteria
Whenever we’re iteratively evaluating responses from an LLM, we need criteria to determine at what point to stop getting new responses.
For this method, I use three different parameters:
Stability criteria: This is the novelty distance that we consider “the same.” None of our new responses will ever have 0 semantic distance from a previous response, so we need to set some reasonable threshold above 0.
Stability periods: Here we’re determining for how many periods, or responses, the stability criteria must be met before the program stops.
Maximum runs: If stability isn’t reached, the program concludes after this number of runs.
Flagging Responses
We want to flag responses not because they’re especially good – we don’t have a way of determining quality – but rather so that a human can review a sample that covers the full spectrum of responses, without having to read every single response.
One way to do this would be to sample randomly. But if we have a small number of distinctive responses, random sampling might miss those.
So instead, I use a hierarchical clustering method that minimizes the variance within each cluster while also performing multiple levels of clustering. This clustering is another type of dimensionality reduction: we’re going from 768-dimensional space to n-dimensional space, where n is the number of clusters.
Each response is classified into both bigger and smaller clusters, and then you can then choose how granularly to sample. If you want to get a higher-level view of the responses, you can sample from the bigger clusters – in the figure below, from the biggest two or three clusters. If you want to see more responses and capture more of the variance, you can sample from the smaller clusters.
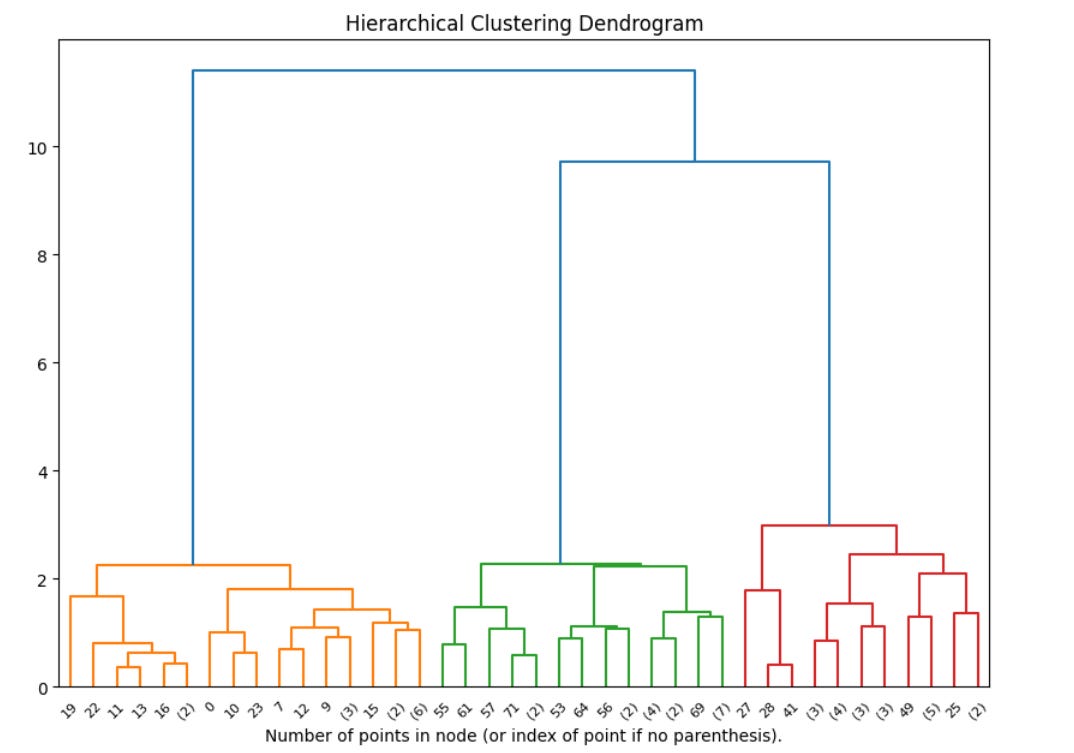
Failure Modes
There are a couple of significant ways that this analysis could fail.
Incomplete Population Coverage: If our prompt perturbation process is inadequate, we may not get the full range of responses. Similarly, if our measure of semantic similarity doesn’t correspond to what we’re actually looking for, or if we end prompting too early (because we’ve set stability criteria or stability period parameters in the wrong place), then – even if our measure is good – we won’t get full coverage.
Inadequate Dimensionality Reduction: I got generally good results using the combination of the semantic similarity model and hierarchical clustering. But I’m not sure if this is the best method for finding outliers. And this is my major concern about this method: I think it’s going to work well at giving a general sense of what the model is outputting on a particular question or topic, but if your concern is that one out of a hundred responses is going to say something weird that you need to look at - for instance, a line with a specific set of bioweapons instructions that the other responses do not contain – I’m less confident that this method will find you that one response. I’m continuing to think about this.
Conclusion
I think if you’re red-teaming LLMs for safety, you should ideally know what you’re looking for ahead of time, and use methods geared at that. But if you don’t know what you’re looking for – if the work you’re doing is more exploratory – this can give you some tools to start with.