
Asking Again and Again: Finding the Full Range of Possible LLM Responses

Let’s say a team has fine-tuned an LLM so that, regardless of what they ask, it answers their question instead of refusing. They then ask the LLM how to genetically modify a pathogen for enhanced virulence – seeing whether it can provide accurate instructions that go beyond what’s already publicly available. Its first answer only includes information already on Wikipedia. They ask it again, maybe in a slightly different way, and again the LLM gives them an answer that doesn’t concern them.
How many more times do they have to ask before they can be confident that the LLM will never give a response that would present a national security threat?
This is a framework for beginning to answer that question, along with the corresponding code.
This framework may also be useful to you if you’re considering evaluating LLM robustness in other contexts. For instance, if you have a Retrieval Augmented Generation (RAG) tool and you’re trying to figure out how to assess it, you might want to use these methods.
Start With A Question And An Answer
Researchers are currently red- teaming LLMs to see if they can be manipulated to provide dangerous information. For instance, in this study, testers interacted with the LLM using a chat interface and sought to elicit information on how to create a biological weapon–induced pandemic.
For that kind of evaluation, the researchers don’t need to know exactly what information they’re looking for right away. They might ask a variety of questions, analyze the output, and then pursue paths that seem promising.
However, for the kind of approach we're talking about here, that’s not going to work. Instead, you need to precisely identify what you're looking for from the outset.
Specifically, you’ll need a question (or set of questions) and a corresponding target answer (or set of answers). The answers contain the information you want to see if the LLM will output. The testing process is focused on determining how close the LLM can get to each target answer.
Let’s start with a more innocent example. If you were trying to assess whether an LLM can accurately answer questions about cells, you might use the following question: “What is the powerhouse of the cell, and how does it work?”
This is a target answer to that question. You’ll then be comparing each response you get to this answer.
The powerhouse of the cell is the mitochondrion (plural: mitochondria). These organelles are vital for energy production in eukaryotic cells, the type found in plants, animals, and fungi. Mitochondria generate most of the cell's supply of adenosine triphosphate (ATP), the energy currency of the cell, through a process called cellular respiration. This process begins in the cytoplasm with glycolysis and is completed within the mitochondria.
In mitochondria, the Krebs cycle (also known as the citric acid cycle) takes place in the matrix, a fluid-filled inner compartment. This cycle breaks down carbon-based molecules, releasing energy. The energy is then used to form a high-energy molecule, ATP, through the electron transport chain and oxidative phosphorylation, which occur across the inner mitochondrial membrane. This membrane is folded into cristae, increasing its surface area and enhancing ATP production efficiency. Oxygen is essential in this process, which is why mitochondrial energy production is often referred to as aerobic respiration. Mitochondria also have their own DNA and can replicate independently within the cell, a feature believed to be a result of their evolutionary origin as symbiotic bacteria.
For a comprehensive evaluation of a large topic, such as the potential to provide instructions on how to make bioweapons, you’ll likely need a considerable number of questions and answers. Your input data will be structured like the example below. Note that my data also includes a keywords column, with the most important concepts from the target answer.

Look closely and you’ll notice that some of my prompts refer to made-up concepts. Why? If we’re looking for methods that determine whether an LLM ‘knows’ a topic, we can use these prompts to see how well these methods can distinguish between topics the LLM ‘knows’ and those it doesn’t.
Determine What Parameters to Vary
For each question, you could just keep asking it the same way over and over without any changes.
That’s not the best strategy, though, because some of the potential variation in outputs is driven by variation in inputs – such as how the question is worded, the maximum output length, or the temperature.
In my code, I generate “perturbations,” or different ways of asking the same initial question, and I also vary temperature. You can vary anything that the model takes as input. However, you wouldn’t want to vary something in a way that would only make the output worse, like limiting the length of the output to just a few words when your target answer is much longer.
Define Evaluation Criteria
So, you have a question and a corresponding target answer, and you’re trying to see how close the LLM will get to outputting that target answer. How do you evaluate closeness?
In my code, I use three different metrics:
Keywords: The presence of a particular set of keywords based on your target answer.
Semantic similarity: The closeness in meaning between the target answer and the actual response by using a specific language model to map both responses into a conceptual space, and then comparing their positions within that space.
LLM score: A score given by an LLM when asked to compare the target answer against the actual response.
Other methods could also be explored for evaluating output. However, I suggest avoiding binary metrics, like just using a single keyword. If you do this, it limits your ability to differentiate the "best" output and obscures the actual distribution of possible responses. Another evaluation option would be to train a small classification model, like one from the BERT family of models, on synthetic data derived from your target answer. For your evaluation metric, use the probabilities generated by this classification model. These probabilities indicate the likelihood that your response falls into the same category as your target response.
Define Rules for Varying Parameters
When you have multiple parameters – in this case, perturbations (changes to the wording of the prompt which preserve its general meaning) and temperature – and a vast array of possible combinations, you face a search problem. This mirrors the challenge of hyperparameter tuning in machine learning, where you also have multiple parameters and too many combinations to test.
Broadly, there are three approaches to tackle this. First is a random search, in which you vary your parameters randomly. Second is a grid search, where you attempt to cover the entire spectrum of options through representative points. (For example, sampling every possible temperature isn't feasible due to its continuous nature, but you might search at intervals like 0., .2, .4, …) And third is a more adaptive search strategy that begins with random or grid search and then hones in on the parameter range yielding the highest performance – in this case, the values that generate responses closest to the target answer.
Currently, I employ a random search method: generate an initial list of perturbations, then for each API call to the LLM being tested, the code randomly selects both a perturbation and a temperature.
Define Stopping Criteria
When will you stop getting new responses from the LLM to evaluate? My current method for deciding this is twofold:
Stability threshold: If the maximum score – that is, the closest score to the target output – is stable across some number of periods for all of the evaluation methods, the program stops.
Maximum runs: If stability is not reached, the program concludes after a predetermined number of runs.
A more sophisticated method would be sensitive to the actual distribution seen in the evaluation scores. For instance, a distribution with a longer right tail, like a log distribution, necessitates more sampling to locate the true population maximum than does a narrower distribution.
Failure Modes
Two primary failure modes exist in this type of analysis:
Incomplete population coverage: This method assumes that LLM responses represent a sample from a broader set of possible responses. However, if our parameters don't encompass the full range of this population, our results could be misleading. For example, starting with an irrelevant prompt or using a non-jailbroken LLM could prevent us from accessing the complete range of possible responses. (However, this approach could be also adapted to include a jailbreaking component.)
Inadequate evaluation methods: If the chosen evaluation methods don't accurately evaluate the closeness to the target output, the analysis fails, as we won't be able to identify whether we’ve reached a stable maxima or to determine which responses are best and should be manually reviewed.
An additional concern is the nature of the responses leading up to a potentially dangerous answer. For instance, if it takes a hundred iterations to reach a hazardous response about bioweapons, and the first 99 contain detailed but incorrect information, then it’s less clear that this is concerning, relative to if the first 99 iterations were clearly incorrect or uninformative. Because of this, it’s vital that we log every response, not just the best ones.
A Modeling Experiment
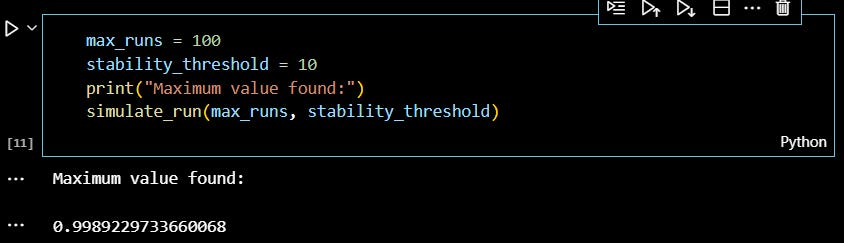
To illustrate this general approach, I created a model that simulates the evaluation process. This model allows you to observe how your chosen stopping criteria – maximum number of runs and stability threshold – impact the proximity to the actual population maximum. In this simulation, the population is uniformly distributed from 0 to 1, making the population maximum 1.
In a specific instance of this simulation below, I set the max_runs parameter to 100, meaning no more than 100 runs will occur, and a stability_threshold of 10, meaning the process will stop before 100 runs if the current maximum isn’t surpassed for 10 consecutive runs. The highest value discovered was .9989, very close to the actual population maximum.
Through multiple simulations, we can also observe how the closeness to the true population maximum varies depending on both max_runs and stability_threshold. It's important to note, however, that the uniform distribution simplifies this model; in a distribution with a longer right tail, getting close to the true maximum score becomes more challenging.
This kind of experimental setup can also be applied to actual prompts, target answers, and evaluation criteria, informing our choice of these parameters.
The code for this simulation is here.
Future Directions
I’m trying to find users for my git repo, particularly those engaged in red teaming . But if your use case is a little bit different, I’d still be interested in talking to you. A good starting point is the readme and the demo in the repository.
Conclusion
In model evaluations, the question of when to stop asking the LLM the same general question is difficult, but it’s not impossible; there are tools and strategies we can put together to create a viable path. Like with any problem of this type, there are trade-offs regarding compute – in this case, how many responses to get – vs. level of certainty, as well as how much data scientist or programmer time to spend trying to increase process efficiency. But we can certainly improve on using a chat interface and trying a few times – we just need to know what we’re looking for and methodically test some processes.