
Using AI To Classify Resumes
And assessing the performance of your model
I’ve been sharing my thoughts about using AI with jobs data, and also on how to construct a model using Large Language Models like GPT and build an assessment. I wanted to merge them together and see if I could get GPT to correctly “predict” my categories for classifying resumes – or, in other words, screen the resumes in the same way that I would.
It worked well enough to make this a potentially-viable use case.
To begin, I generated simulated resumes resembling those I saw a few years ago when I was looking at applicants for federal data scientist positions. I then tested to see if I could get GPT to correctly classify them the way I would now – as candidates I would or would not want to interview.
The model was accurate at predicting the correct label for those I had coded as "yes," even though most of them did not have the job title of "data scientist." It was not as accurate at predicting the "no's," but it was still accurate enough to be potentially useful, depending on the applicant pool.
Possible Applications
This approach has multiple applications when it comes to government hiring.
1. It can speed up the screening process to expedite hiring. This is a huge deal, because your strongest candidates have the best other options, and you don’t want them to accept another offer while you’re still screening resumes.
2. If you’re limiting the number of applicants due to manpower constraints – for instance, wanting to use direct hiring authorities but not read 1,000 resumes– then using AI as a screening tool can allow you to accept far more resumes.
3. You can use this to compare the applicant pools from different types of announcements for the same position type. For instance, suppose you want to test whether announcements listing telework do better than others? What about announcements that are more “technical” that list particular tools and software? You can quickly crunch through thousands of resumes from different hiring announcements to compare the applicant pools.
In all of these cases, though, GPT isn’t magic, and the same evaluation processes apply as other types of models. You can only test if GPT is evaluating resumes the way you would if you label some data - that is, if you classify resumes yourself as “yes” or “no” and then compare those results with GPT.
Once you’ve done that, you should periodically sample and verify the model is still working. If you have another hiring announcement with new resumes, you should pull a random sample, label them, and evaluate GPT's performance*.
This lets you ensure that your model still works, and that you’re not getting “out-of-sample” data, or resumes that are significantly different from the ones you initially tested your model on and that your model can’t reliably assess.
Producing Fake Resumes, Labeling Fake Resumes
I used GPT-4 to help me generate 20 fake resumes. I used this general prompt: “Please compose a sample resume using real years and institutions for the following person. Please go into a lot of detail and make this more extensive than you would think to, particularly the descriptions of what they're doing at their jobs.”
I appended this prompt to names I’d randomly generated and biographical data that I’d written myself including job title, undergraduate degree, and a description I’d written of each person. I had these in an Excel spreadsheet, and combined them with the prompts in Python in order to send them to the GPT-4 API.
For instance, this was the second part to one of my prompts:
“Brayden Wright currently has the job title of Data Scientist. They have an undergraduate degree in Political Science. This is a description of them: Despite being in a data scientist position, this person is in more of a Business Intelligence/Business Analyst role. While they list Python in their skills (and don't characterize themselves as a beginner), the tasks they list in their former and previous jobs are more related to building dashboards in drag-and-drop tools and making reports in Excel. They describe in depth some of the business impact of their Tableau dashboards. They have taken Tableau training. They are mid-career.”
There were two major challenges with the resume generation. The first was that, even specifying to the model that it should make the resume long and go into detail, GPT-3.5 was writing me really short, general resumes of the type I’ve rarely seen. But GPT-4 did better. For instance, this is a sample from Brayden’s:

It’s not the best resume I’ve seen, but it’s not unrealistic, either.
The second issue I ran into was that the style for all of the resumes was initially really similar. I got them differentiated to some degree by specifying if I wanted an academic result that listed publications, or a USAJobs-style resume that went into a lot of detail. But ultimately, real resumes real resumes exhibit more variety – and this variation could potentially impact the model's performance.
After I generated the resumes, I labeled them – and in some cases, I went back and rewrote prompts and re-generated resumes in order to get the 20 resumes I wanted. The goal was 10 I could classify as ‘yes” and 10 as “no.”
I purposely made some of these close calls, like the prompt above for the business analyst with the data scientist job title. I also purposely varied job titles and academic backgrounds in other ways, such as giving most of the people I classified as “yes” job titles other than data scientist, and not making academic background predictive of labels. This is consistent with what I’ve seen in candidates as well.
Getting GPT to Classify Resumes as “Yes” or “No”
This was how I asked GPT to classify resumes: "please respond YES if this candidate has worked in a role where they have been coding in R or Python to solve data science tasks and NO if they have not or if you are not sure."
I tried other prompts, but they all performed basically the same.
GPT-4 was good at returning answers in the form requested - that is, a YES or NO. At worst, it would say something like “NO. The resume does not provide evidence of the candidate's ability to immediately start building tools in R or Python to meet business needs, nor does it demonstrate an understanding of the technology and the ability to communicate with stakeholders. The focus of the resume is on government finance, financial analysis, budgeting, and program management.” (This was in response to one of the other prompts.)
But it was easy to automate cleaning this and just return the “NO” part.
Assessing the Results
I assessed each prompt and automatically generated what’s called a “confusion matrix” - in this case, a two-by-two grid showing the four possible sets of outcomes.
These are:
True positives, where I labeled a resume as “yes” and so did my model,
True negatives where we both labeled them as “no”,
False positives where I said “no” and it said “yes”
False negatives, where I said “yes” and it said “no”.
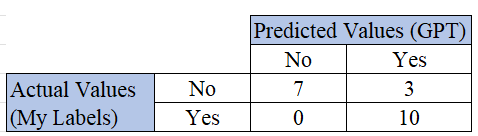
The following confusion matrix, which I got for the prompt above, was typical of the results I got from the prompts. We see 10 true positives, 7 true negatives, and 3 false positives.
Those three false positives are the ones it got wrong: resumes I labeled “No” and GPT labeled “Yes.”
However, remember, the data is fake! Your data might look nothing like mine, in which case your results might be better, or they might be worse. What’s more interesting is what it got correct and what it got wrong.
First, it had no trouble figuring out that people in roles not called “data scientist” were still doing the tasks it was looking for.
Second, it correctly determined that accountants and budget analysts, who are data subject matter experts, did not have data science skills – and also that analysts in “analyst” jobs and business intelligence folks in “business intelligence” roles also do not.
Third, it struggled at more nuanced distinctions.
For instance, it characterized an engineering resume where the candidate was working in MATLAB and mentions Python but doesn’t specifically describe anything he’s doing with it as “yes”, as well as an ORSA who is mostly using Excel, and the example I showed earlier of someone in a data scientist role who is doing mostly business intelligence.
So if you’re trying to distinguish between those folks in your hiring pool vs. more central examples of “data scientists”, it might not do well. You can try other prompts that might, but so far I haven't found any.
But I think the results here are good enough to show that there’s a “there” there - something that might work with real data.
If I had real data, I would keep going and also try other kinds of prompts – for instance, to see if it can tell me how many years of professional experience candidates have in data science-type roles, or if it can narrow in further on more specific kinds of non-technical or technical experiences.
Classification and Assessment in General
Text classification has a lot of practical use cases - either by itself, or paired with human judgment.
Resume screening is a huge one.
Essay grading, like with SAT IIs or AP exams.
Flagging jobs to apply to.
The question remains, can we develop a model that performs well enough to be viable for our specific use case?
The answer to this is going to be “in some cases yes and in some cases no”. But by setting up your problem like this – labeling some data, trying some prompts, assessing the results – you can start to answer that in a way that’s rigorous, and where when you continue to sample and label and test as you get new data, you can determine how well your model continues to work.
*As with any project where we’re using labeled data, our model evaluation is only as accurate as our human-generated labels. If our labels are wrong or biased in some way, our model evaluations will consequently also be incorrect.