
Repeated LLM Sampling and the Challenge of Meaningfully Capturing “Distance"
Large Language Models (LLMs) exhibit bounded variation in their outputs. Ask one repeatedly for pasta recipe ingredients, and you'll get different combinations each time—some with garlic, others with parmesan, varying in complexity and style. But you'll never see Cheetos listed as an ingredient, much less arsenic.
We develop strong intuitions about these boundaries through working with the models. The space of possible outputs, while diverse, seems far more constrained than either all random text strings or even all semantically coherent responses. But I've found it surprisingly difficult to formalize these intuitions, and this makes it more difficult to do test and evaluation—to predict what a model might output—than it feels like it ought to be.
To explore this concept, I asked GPT-4o-mini to generate a list of ingredients for a pasta dish 1,000 times. The results mostly matched my intuitions: parmesan, black pepper, and butter appeared frequently, although I was surprised at how infrequently tomatoes appeared. Black olives and vegetable broth showed up occasionally.
And the things I wasn’t expecting to appear didn’t. No Cheetos, no arsenic, no ingredients that would be nonsensical in pasta. Without formally testing millions of samples, I was confident these wouldn't show up, ever.
But my admittedly limited attempts to formalize these intuitions didn't work, and it feels like this gets to a problem with dimensionality reduction for text data.
Why Do We Care What the 'Output' Space Looks Like?
There are two main reasons we care about understanding the space of possible model outputs:
Testing Coverage: For testing generative models, we typically have a set of test cases covering the types of inputs we want to give our models. But even with model temperature at zero, we get different answers each time. How "close" these outputs are seems like it should determine how many samples we need per question to be confident we've seen the general range of responses. This isn't necessarily crucial for your testing process—if you just need overall accuracy metrics, testing each prompt once might suffice. But for higher certainty at the question level, you might want something more rigorous than "test each question many times"—and ideally, something less expensive in tokens.
Output Aggregation: When sampling multiple times, we might want to identify core ideas that appear across responses and distinguish truly different answers from rewordings. In an ideal world, we could compute something like an "average" response capturing the central tendency.
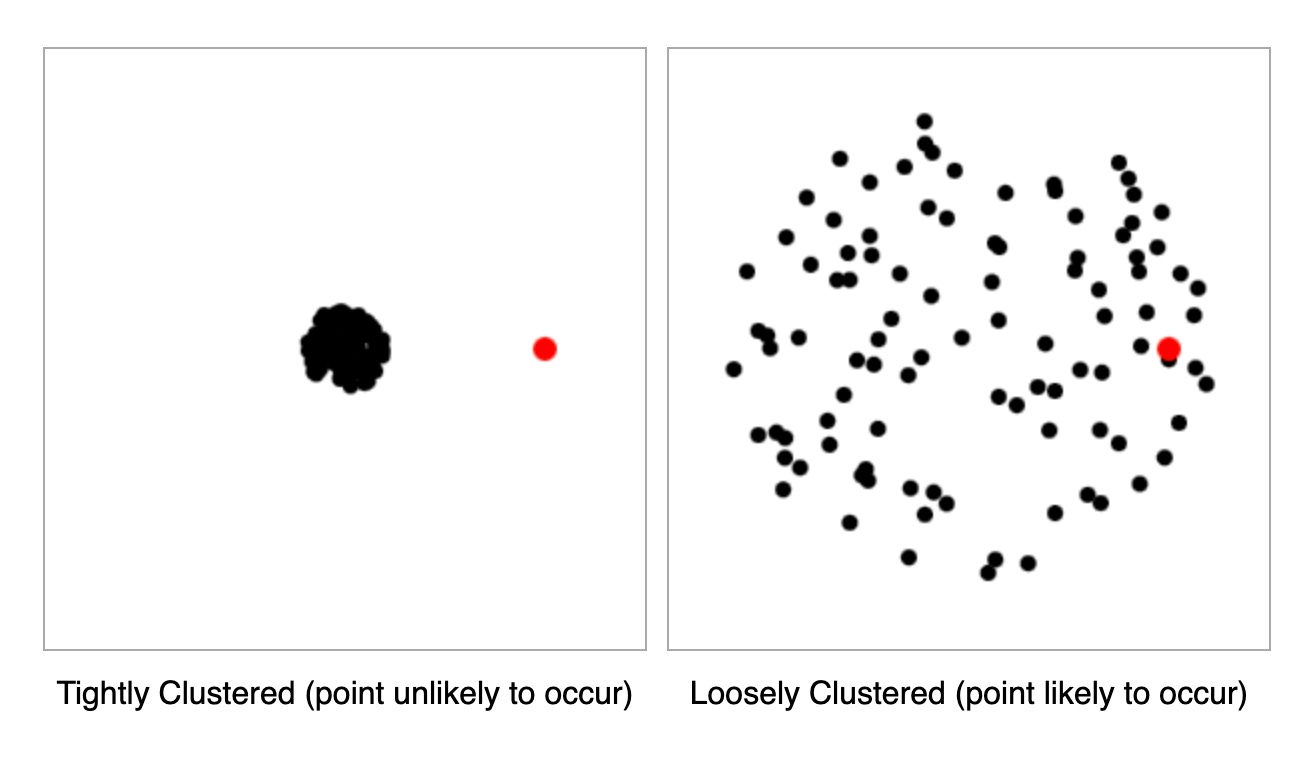
But while these concepts of closeness and variance are easy to grasp, they're hard to formalize. What does it mean for one piece of text to be "close" to another? What does "the most common answer" mean when dealing with high-dimensional text data where you're never going to get the exact answer repeating?
The Challenge of Measuring String Distance
Two approaches to formalizing string differences are lexical similarity and semantic similarity.
With lexical similarity, using the recipe example, all we can do is look at the number of ingredients that overlap across recipes. We can compare each recipe to the first one, and give a point for every ingredient in either recipe that is not found in the other. If there are four ingredients in the base recipe that aren't in the comparison recipe, and vice versa, it has a score of eight.
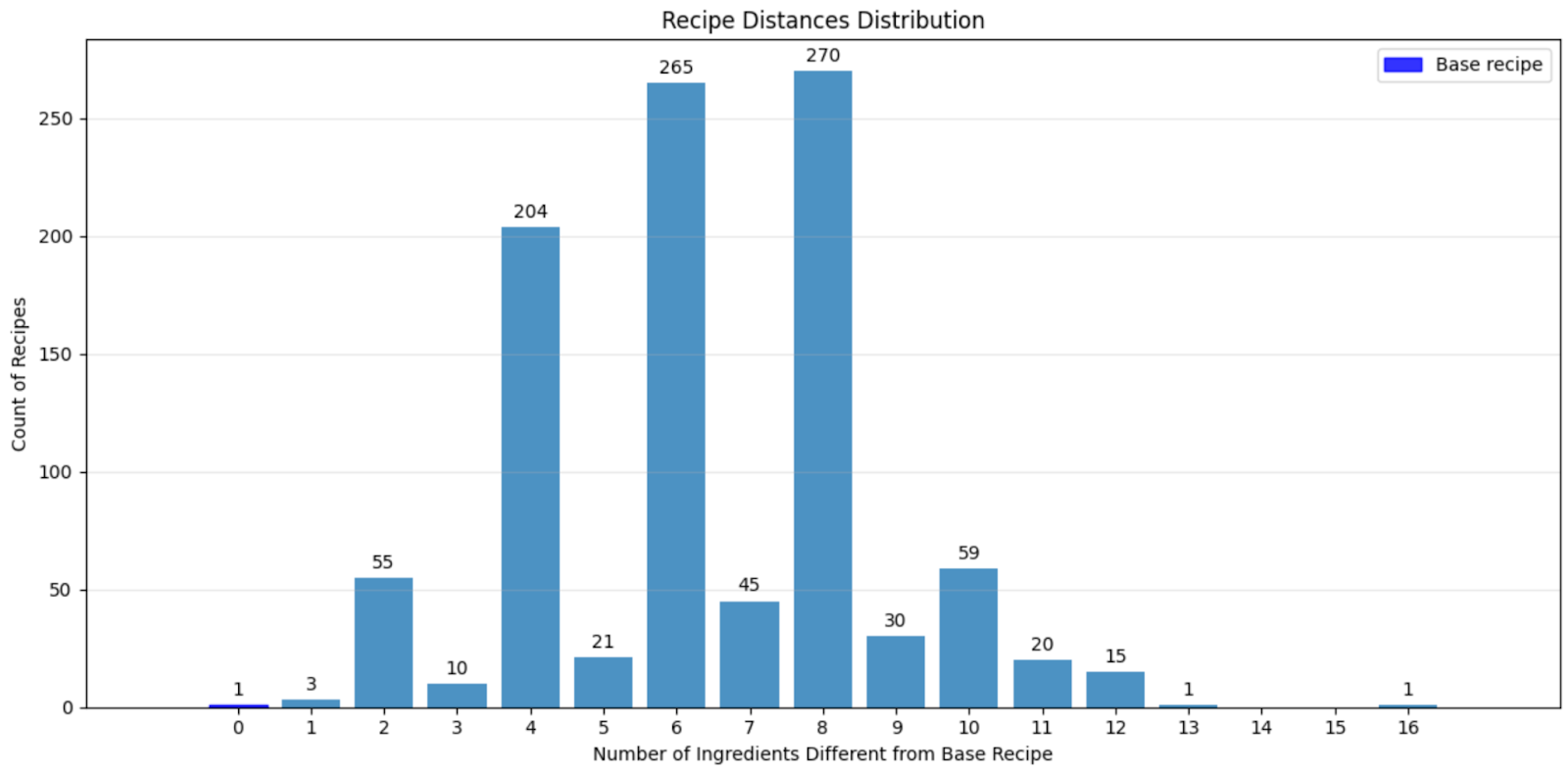
The problem isn't that lexical similarity tells us nothing—it does give us some information about overlap patterns. But it can't necessarily tell us what recipes are similar: if two recipes both have salt in them, that's not a very meaningful similarity relative to if they both have parmesan cheese. (We could look by rareness of ingredient, but both of those ingredients are quite common in our data.) And it definitely can't tell us what ingredients that we haven't seen yet are more or less likely to appear in later samples.
Semantic similarity feels like it should solve our problem. After all, embedding spaces are designed to capture meaning relationships - "garlic" should be closer to "garlic cloves" than to "garlic socks." And for these simple cases, it works as expected.
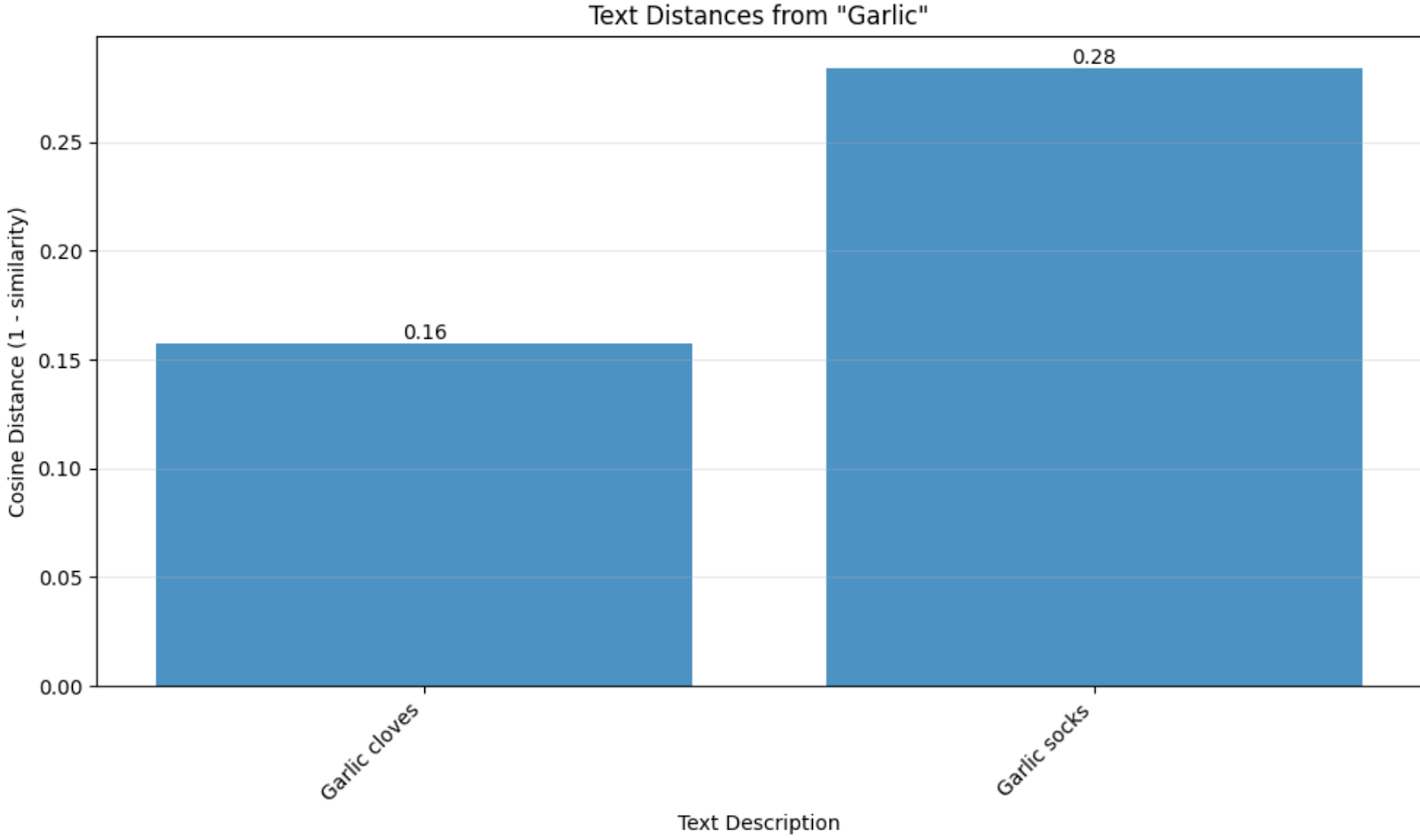
But embedding spaces fail when they capture general semantic relationships, not the specific constraints of our language model + prompt combination—in this case, the pasta recipe. While 'garlic' and 'Cheetos' might have similar distances in embedding space as food items, this doesn't reflect their dramatically different probabilities in LLM-generated pasta recipes.
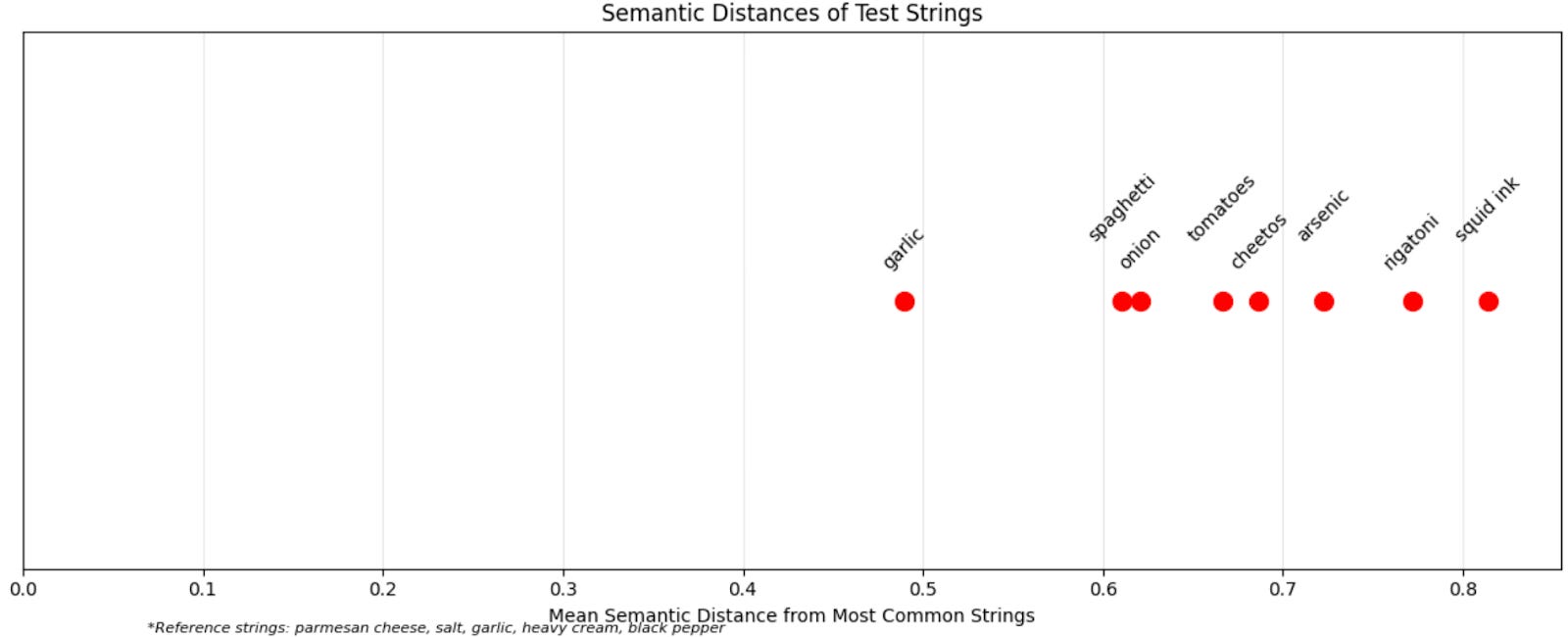
My testing shows the gap. Using mean-distance-from-top-ingredients scores, "garlic" is closest, with "spaghetti" and "onion" nearby. But "tomatoes" and "Cheetos" end up similarly distant, and both "Cheetos" and "arsenic" are closer than "rigatoni." Worse yet: frequently-returned ingredients are on average further from the top ingredients than rare ones. We can't work backward from these distances to predict what the model will output.
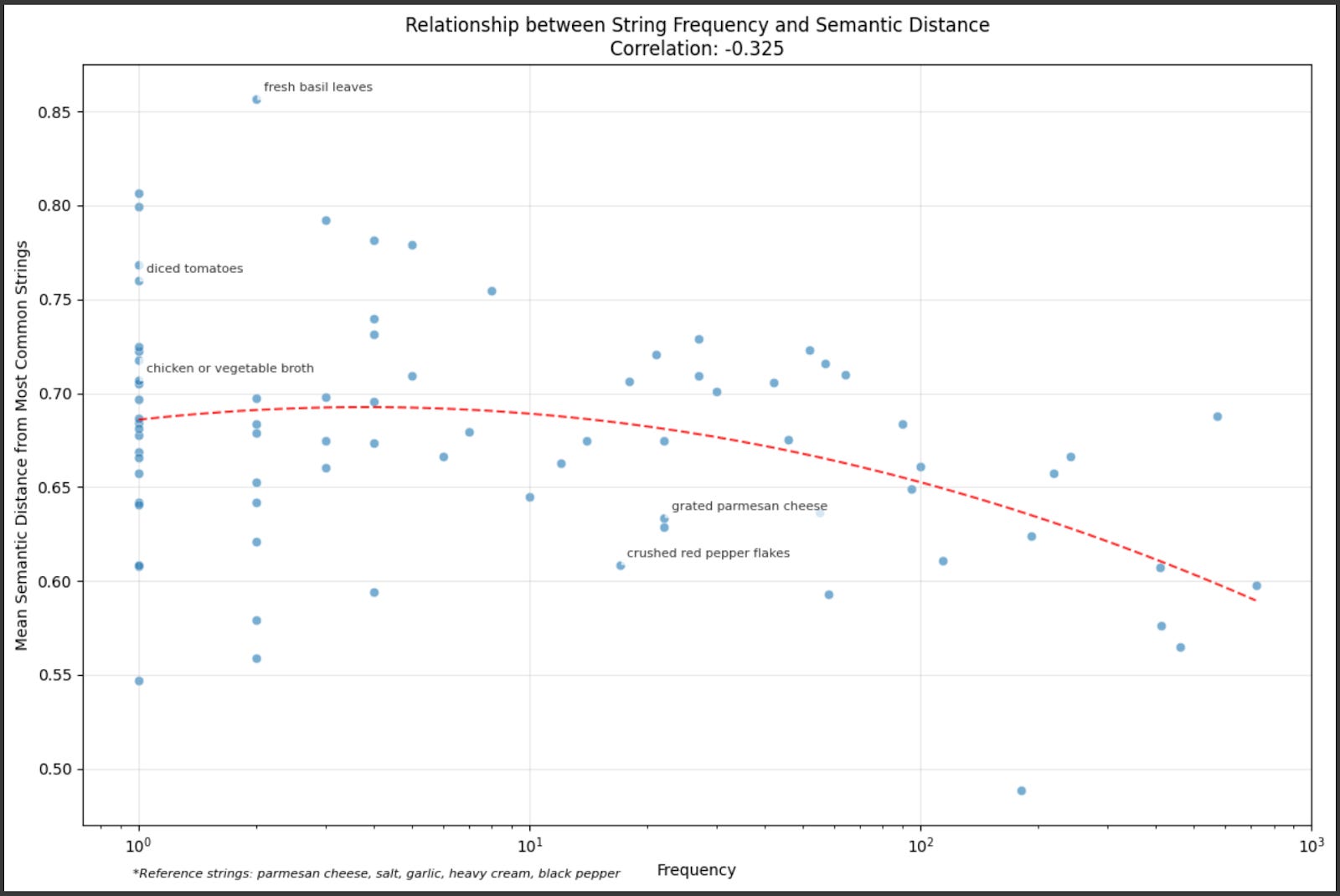
This is also a limitation when trying to aggregate multiple outputs. Ideally, semantic similarity would let us identify duplicate ideas, compute meaningful averages, and recognize truly distinct points. But our current metrics can't reliably support these operations—they don't capture which aspects of responses are truly equivalent versus meaningfully different.
This isn't to say these challenges are unsolvable—just that general-purpose semantic similarity metrics or embeddings alone may not capture the particular patterns that emerge from a specific LLM responding to a specific prompt.
Why Classification Works (Despite Feeling Insufficient)
When we reduce our rich space of possibilities to simple categories—"normal ingredient" vs "something else", "refusal" vs "non-refusal"—it feels like we're discarding valuable information. We're throwing away all that nuanced understanding of how outputs relate to each other.
But for most practical applications, classification works. It’s how I would test to see if a model is reliably refusing when it should, or whether it’s sufficiently polite to users: make it a classification problem, sample a few times each if you need the additional precision associated with that additional sampling, and the estimates you’ll get will be sufficient.*
The limitation of losing all of that “distance” information appears mainly when testing for extremely rare events. If you want 99% confidence that the probability of outputting "arsenic" is below .001%, you need 460,515 straight negatives**.
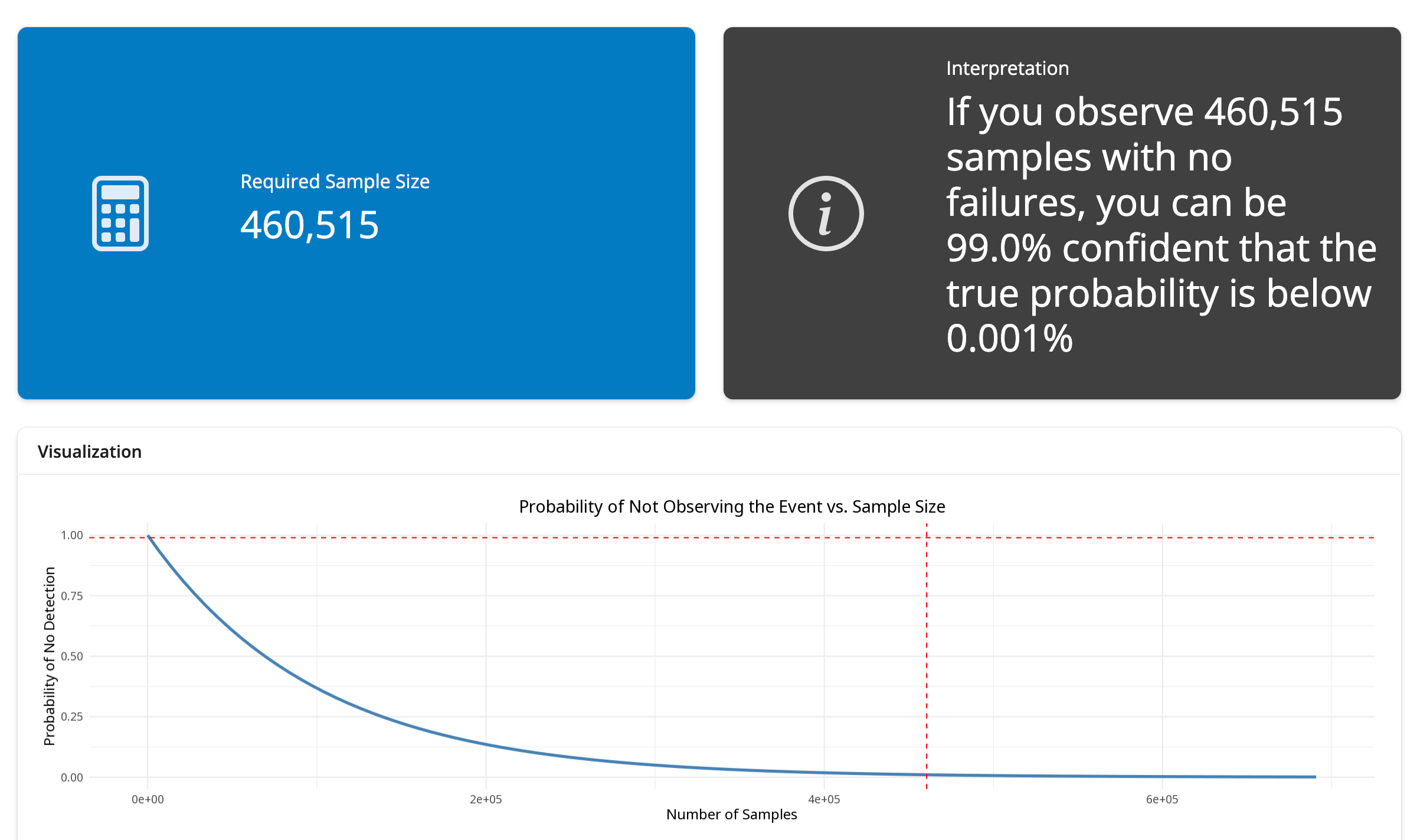
But my intuition tells me testing hundreds of thousands of times is unnecessary—I feel certain that our pasta prompt will never output "arsenic." This gap between my strong intuitions and our formal metrics suggests I'm missing something fundamental about LLM output spaces that I haven't yet found a way to measure or test.
_________________________________
*And to figure out how many times you need to sample to see the full response space, test the model repeatedly and use either manual review or an LLM-as-judge to get a good sense of how many tries it typically takes to see all the different types of answers possible.
** You can play with my dashboard/calculator if you want to try other confidence levels and probabilities.
My code is here.