
Evaluation Can Be Simple Even When the Model Isn't
Assessment, Bias, and Communicating Results
Edit: I accidentally sent this out before it was ready! I changed the title and made some minor changes to the text.
Let’s say your resume-screening process is named “Aris.”
Aris assesses incoming resumes and decides whether they pass to the hiring manager or fail, ending the candidacy. We want to determine whether Aris is making decisions in line with the preferences of the broader organization or its leadership, or with prevailing employment law. Does it matter, for the purposes of evaluation, if Aris is a person in HR, versus if Aris is actually ARIS (Applicant Resume Intelligent Screening), an LLM-based tool?
Yes and no.

First, there are two significant commonalities between Aris and ARIS.
Explainability: Neither is “explainable”. You can give Aris/ARIS instructions and ask what they’re doing, but their responses may not accurately reflect their decision-making processes.
No holistic measures of bias: You can’t holistically evaluate Aris/ARIS for bias and call it a day. You could give Aris an implicit association test if they’re a human, or ask ARIS leading questions to see if they’ll say something offensive, but the only way to tell if their specific decisions are biased is to evaluate those decisions directly.
There are some ways, however, that it could matter whether Aris is a person or a bot.
More damage more quickly: If Aris is a person, that limits the damage they can do. They can’t read through 100,000 resumes a day, process them badly, and destroy a large company’s hiring process. If ARIS is a bot, they can.
Different failure modes: We’re very familiar with human failure modes – Aris may do poorer work when they’re tired, on Friday afternoons, or if they have a backlog of applications. We’re less familiar with failure modes associated with new forms of AI.
But we still have the processes we need for evaluation. These include defining success criteria, collecting data, measuring performance, identifying errors, and ongoing monitoring.
A Classification Model Is A Classification Model
Below is the most basic way to evaluate the most basic model – our binary classification, “interview or don’t interview” model. Our four categories are as follows:
True positives: People who should have made it through our screening process and did.
True negatives: People who shouldn’t make it through and didn’t.
False positives: People who shouldn’t pass the screening but did.
False negatives: People who didn’t pass, but should have.
The confusion matrix is a way of visualizing those categories.
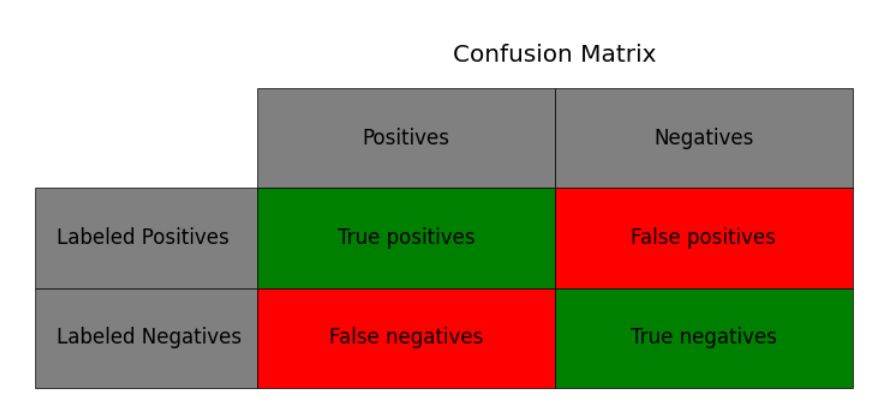
To determine which category applicants fall into, we compare the process's performance with our "labeled data." This labeled data represents the ground truth expression of the organization's values, or the decisions it wants to make. To evaluate the model's performance, we compare the number of people in each category.
Our definition of "good" performance will vary depending on the use case. When there are far more qualified applicants than interview slots, minimizing false positives (subpar candidates passing the screening) may be a higher priority. If it’s the opposite, and we don’t have a lot of strong candidates, then we might care more about minimizing false negatives, or qualified candidates we turn away.
Even for advanced models, evaluation often relies on binary classification. If you’re using facial recognition tools to find matches or predicting whether someone has a particular condition based on analysis of x-rays, the technology may be complicated, but the evaluation piece will still come down to these same metrics.
What Does “Bias” Look Like In This Context?
In classification, bias occurs when the model inaccurately assesses certain groups more frequently or differently than others.
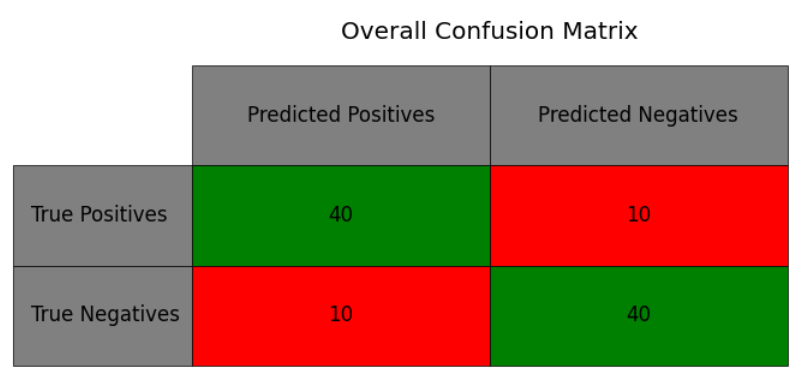
Below is an example of what this looks like. In this first chart, we see overall model performance. This is a model that’s accurate 80% of the time, 80% of the people it passes should have passed, and 80% of the times it says “pass”, it was correct to do so. (These numbers happen to be the same in this case, but they don’t have to be.)
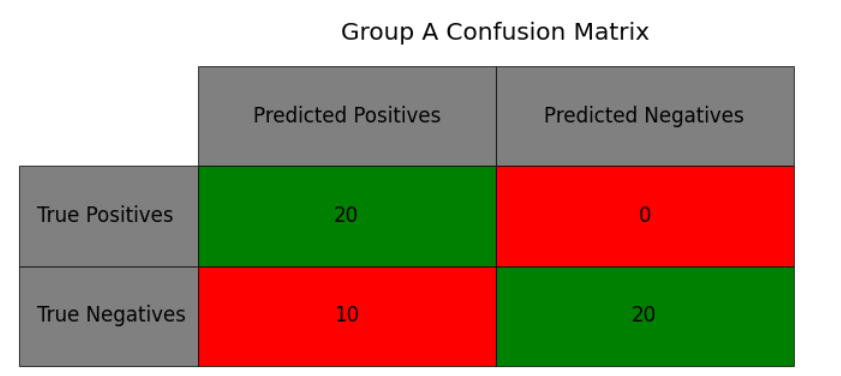
But when we break it down into two component groups, we see a problem. Group A, below, only has one type of error, false positives. When it advises not to interview or hire, it’s always accurate — but it’s also passing a lot of people through who it shouldn’t.
And we see the issue inverted with Group B. Here, whenever the model passes someone, it’s always correct — but it’s not letting a lot of people through who it should.

Although the model performs okay overall, it systematically distorts the hiring pool. If our screening process represented our values, 40% of the people who passed would be from Group A, but instead, because of our model, it’s 60%. As I’ll discuss below, there are multiple ways of dealing with this.
The Problem With “Labeled Data”
But wait – you may have noticed in the previous section that we treated labeled data as the ground truth. What if it’s not? What if we labeled the data wrong, and it’s not consistent with our values, or potentially with the law? If our past hiring decisions were biased, the AI tool will inherit that bias.
So when we’re training or testing AI (or any type of model!), we need to be really careful about where our labels come from. That said, the more we know about each step of the process – the more data we have on applicants and decisions – the better we’re going to be able to assess those processes and determine whether we’re comfortable with using those labels. Certain types of AI models can give us feedback on points of uncertainty, or observations that we should take a second look at because of a big discrepancy in the prediction vs. the label – and those may be observations where we made one choice but should have made another.
What Do We Do If There Are Differences in Performance by Group?
So what do we do if we figure out that our model is performing differently on different groups? Broadly, we have a few different options:
Don’t use it at all. If you already have a process for doing something, and you were hoping AI (or a new type of AI) would be faster, cheaper, or more accurate, but it turns out it has this problem, don’t use it.
Modify it. If this is a model you’re training, maybe you can adjust the training data or use a different model type. Another way to mitigate bias is by using different thresholds or cut-off scores for different groups**. Or maybe you change the threshold for everyone: it’s possible that there’s only bias in a certain range: like, if you only use it on the worst-scoring resumes, it’s performs well. There are different technical approaches here, depending on your use case.
Use it anyway. Sometimes, variable group performance doesn’t harm anyone. I worked on a model that predicted whether a set of fingerprints was going to need to be retaken due to low quality. We’d like to retake your fingerprints right away instead of making you come back at a later date and inconveniencing you. In that scenario, if our predictions weren’t as good for some group, that wouldn’t necessitate throwing the model out completely. First, it doesn’t negatively affect you if we use the model on someone else. Second, the model still might be good enough to provide a benefit, even to the groups it’s less-effective with.
How to Increase Transparency
So you’ve done testing, you’re comfortable with performance, you’ve corrected any issues you ran into. You’re sold! But you probably need to sell other people on this as well. How can you achieve that?
Documentation: What level of detail to go into depends on the sensitivity and the audience, but you should generally be able to share information about where the validation data came from, summary statistics/performance by relevant groups, and examples of how changing certain variables does or doesn’t affect the outcome.
Letting Stakeholders Test: Again, the appropriateness of this depends on the use case. But if this is high-stakes or the kind of decision where there needs to be public accountability, you can build a test environment where users – and this could be your own internal stakeholders, or the public – can directly interact with the model, submit data, and see the outcomes.
Monitoring: Data, like resumes being submitted, change over time. You should have processes for doing ongoing checks to make sure your tool is still doing what it’s supposed to do – and you should share with your stakeholders how you plan on doing this.
Many people are inherently suspicious of AI tools. And they’re not wrong to be suspicious! A lot of things that get treated solely like technical decisions — what training data to use, what thresholds to use for classification models, what level of different group performance is acceptable — are not solely technical decisions at all. Therefore, they are also not solely the province of technical folks but, correctly, things that a broader set of stakeholders can and should contribute to.
What About Chatbots?
But what about chatbots? How do you assess a chatbot for bias?
Well, first, you might not have to. If you’re just using an LLM to power a use case like classification, it doesn’t really matter if it can be baited into saying offensive things. This isn’t a person whose secret beliefs you’re uncovering – it’s a language model which was trained on human text.
But what if you need a chatbot for a specific customer- or internal-focused tool? While “chatbots being offensive” is a difficult problem to solve in the case of foundation models like GPT-4, because the whole point is that they’re available for a wide range of use cases and keeping them from being offensive would mean a lot of trade-offs, that’s not true for your narrow-use customer service chatbot or other tool. For a chatbot with a narrow scope, you can train a classification model to filter out potentially offensive queries before they reach the chatbot. You can also run the same kind of model on all of your outputs to make sure nothing bad is getting through to your users.
This becomes more of a problem in cases where there’s a lot of ambiguity around what’s offensive, or where you have an audience with heterogeneous perspectives. For instance, content moderation on a global platform is inherently fraught, but it’s fraught regardless of whether you use AI or people.
Conclusion
This is not a comprehensive take on bias in AI, or even with respect to LLMs. There are broader issues that being a data scientist doesn’t give me a perspective on. But for the topics I’ve discussed, there’s a lot we know already about these issues that transfers well to new models. And even if the model is a black box, we can actually still figure out quite a bit about what it’s doing, and we can and should both evaluate it and communicate that out.
______________________________________________
*There are also very explainable ML models, where it is possible to see exactly why each recommendation is made. And there are situations where it’s worth it to take a hit to accuracy if it gets you more explainability.
**Don’t do this if this is not legal, though.