
No, I Don’t Read My Code
And I’m Happy to Tell You Why
Last week I was giving a lightning talk about DC real estate data — how good the data is, and how, with Claude Code, you can quickly answer questions and build great-looking figures. At the end I had a slide listing the tools I’d used, and I called out Leaflet, which I used to make the maps. Someone in the audience asked me what Leaflet was, and I told them I didn’t know and they should ask Claude Code.
I was joking, sort of. Leaflet is a JavaScript library that integrates with OpenStreetMap, which provides the map tiles I was using. I can tell you exactly what I built with it — a choropleth map, a proportional-symbol dot map, and a flag-symbol map (one country flag per owner, sized by assessed value).
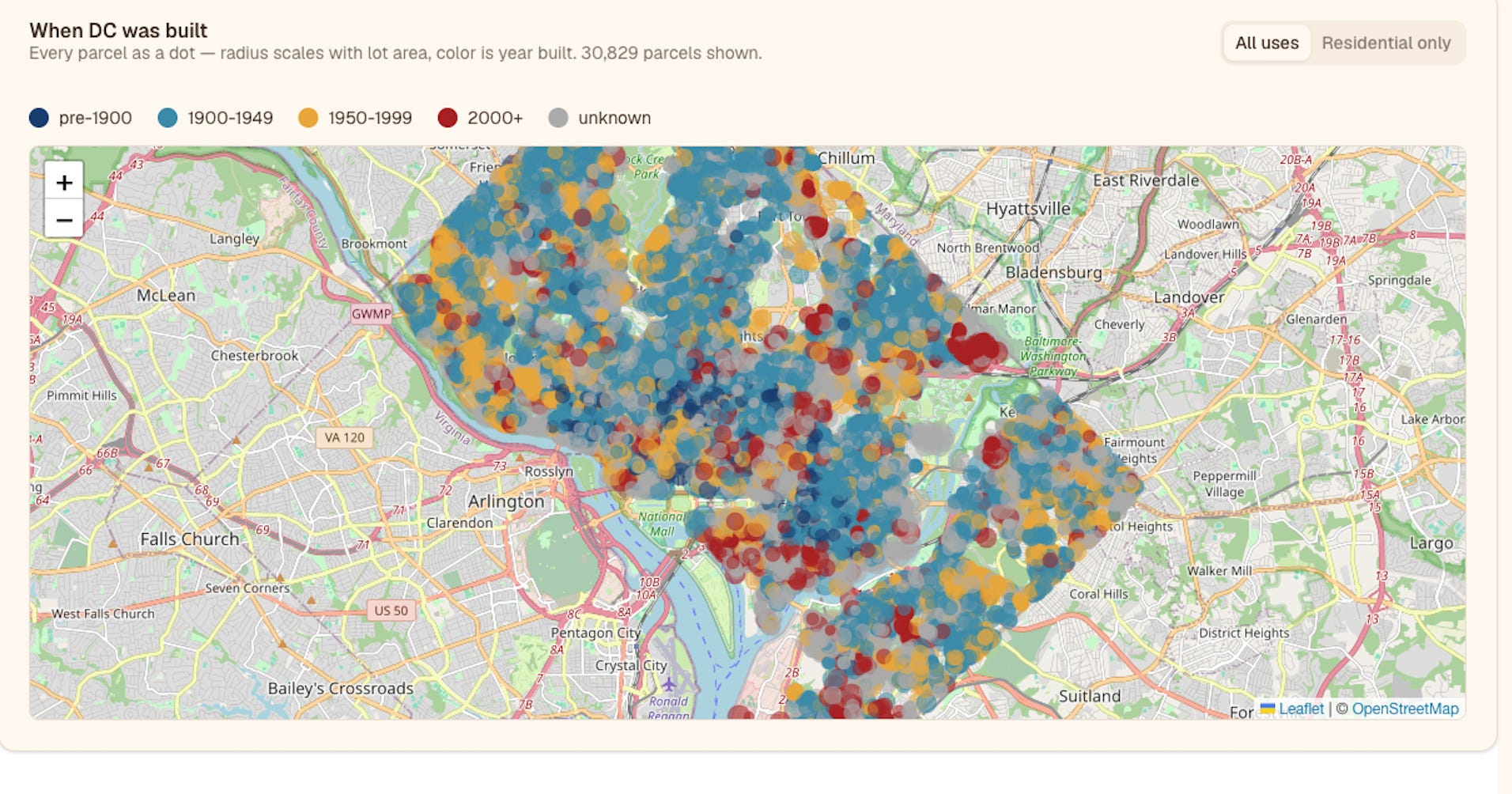
But if you ask me about the code itself, I can’t tell you much. I can’t tell you the syntax. I can’t tell you which Leaflet functions I called, or even very much about JavaScript as a language. That’s because, with Claude Code, the level of abstraction I’m working at is very different from when I was writing code by hand. Sometimes I glance at a few lines of code while Claude Code is writing it, or when we’re refactoring together. But I almost never open an actual file and read it from start to finish.
I think this is reasonable. And I think if you’re an engineering leader — or anyone who talks to people about coding practices — part of your job is asking which practices still make sense given where the tooling is and where it’s going. What were we trying to get by reading code, and are there better ways of getting it now? How does this depend on what we’re building and on the stage of development of the product? The answers to these are different than they were two years ago, and they’re going to keep changing.
Modeling vs. understanding
I’m told that coding sorting algorithms is a standard activity in introductory computer science classes — there are sorting algorithms of different degrees of efficiency, and students come out of it understanding how they differ and how to build each of them.
Even before LLMs, that wouldn’t have been especially useful to my work as a data scientist. The things I needed to know about sorting algorithms were essentially: what’s the syntax, and how do they behave on my data? I can still recall a couple of the parameters in the sort function that I used the most, and at one point I probably needed to know what happens if you sort a series with both numbers and letters. But that’s as far as I would have gone.

Are data scientists bad coders because they don’t know which algorithms their tools are using to sort, and couldn’t derive them?
I don’t think they are. What coders always need isn’t full understanding — it’s to be able to model their code at a level appropriate to their goals.
What I mean by modeling is: I hold a picture of what my code does at the level of inputs, outputs, and behavior. If I run this pipeline on this data, here’s what I expect to come out. Here’s what would surprise me. Here’s where it’s most likely to break, and here’s what I’d see if it did.
I used to get that in part by reading my code. How I get it is different now. And how much of it I need depends on what I’m building.
For a prototype — something exploratory I’m building to figure out what I want to make — I might barely need it at all. What I’m making might just be a glorified wire frame, meant to show the layout and what happens when you click. For something in production, I need a lot more: I know from experience that, while Claude Code can help enormously with this, I still need to model my code well enough to catch issues and build on it. How much that changes as the tooling improves, I don’t know.
Your attention is now expensive
I write so many more tests than I used to.
It’s not that I never wrote tests before LLMs. It’s that they weren’t a regular part of my practice as a data scientist. Now they’re a default. Anything breaks, write a test for it. The cost of writing the test is cheap, and the benefit — never manually testing that thing again, never worrying it broke without my noticing — is high.
This is because my attention is now what’s expensive.
Old practices were optimizing against the cost of writing code. That cost is gone. Most things in the development workflow that used to be expensive — tests, refactoring, documentation, exploration — are now cheap. The only expensive thing left is your attention.
That changes which practices are worth investing in. The answer to “what should we do more of?” is: almost everything that protects code quality without costing a lot of your own attention.
Write more tests, no matter what kind of code you’re writing. Write them as a default, not a chore at the end of a project. Refactor more often, in smaller chunks, as a normal part of working. Open more pull requests, in smaller pieces, and if you’re running an engineering team, raise the bar for what gets merged — because the cost of improving code has dropped.
Your attention is the budget. Spend it on what only your attention can do: what to build, whether the artifact is meeting the goal, where the design is wrong. Don’t spend it on the things the tools now do for you.
And for each practice we use, we should be able to answer: what are we trying to get from this, and is this still the best way to get it?
I got asked to give that lightning talk about four days before the event, and I put it together in about an hour. The point I wanted to make was the utility of the data and the ease of building with it. That’s all. It was uncomfortable having only a surface-level understanding of my code, but that really was the only level I needed to make that point — and if I’d needed to have more, I wouldn’t have had time to make it.
To people who haven’t gotten on board
There’s a lot of evidence about what these tools can do. The benchmarks have been moving for two years. There’s testimony from developers across the field. For me, there’s my own 2,000+ hours. All of it points the same direction, which is that these tools are just really good.
But I still see a lot of dismissal from software developers, including sneering at people who don’t read their code.
I have some sympathy for where the dismissal comes from. When you have a skill that feels central to your professional — and maybe personal — identity, and now a piece of software can do it, and so can people who don’t have your skills but use that software — it’s hard. This is something a lot of us are dealing with right now.
But nonetheless, that is what happened and is continuing to happen.
And if you’re going to stay in this field — and stay in a position of leadership — you’re doing the people who depend on you a disservice if you don’t acknowledge what’s happening. They need your help figuring out what comes next: what good practice looks like in this new shape, what we should be teaching, what we should be hiring for, how to make the cheap practices stick. That work needs people who care about doing things right and are willing to update their picture of what that looks like.
I think there is a big difference between not knowing how like a bubble sort works (basic comp sci concept but not useful to a data scientist), not understanding your graphing code (might be ok assuming you’re sure the right data is being plotted the way you want and you can verify it by just looking at it?), and not understanding the polars/pandas/sql code that is doing the analysis.
For example, I have used an LLM to like translate a plotly graph to altair (so I could have shaded error bars which plotly doesn’t support) but it was a long back and forth and part of my wishes I just actually learned Altair rather than outsource to an LLM.
I think the jury is very much out on the productivity increases of LLMS for coding and there is evidence using them inhibits learning and understanding
https://www.anthropic.com/research/AI-assistance-coding-skills
LLMs can work for coding because you can always test the code - I think you are right about the importance of tests. But I want to understand any actual analysis code so I can make sure the analysis is correct! The LLM doesn’t understand anything; only humans know what our true intent is. If we divorce ourselves from understanding the analytic code than the risk is high that subtle but believable errors will creep in.
I also disagree to we have no choice but to learn/use these tools and change how we work. Companies are already setting limits on tokens and realizing that maybe all this AI spend isn’t worth the money. I use coding tools for what I think they are good at - and that’s what every data science should do. No pressure to use it because of FOMO.