
Mapping Testing to Threats
For pre-release testing, the threat model should inform the methods

This discusses pre-release testing strategies for Large Language Models to assess whether they can produce sensitive, national security-related content. It explores how whether black-box methods will perform sufficient assessment depends on assumptions about the structure of LLMs and jailbreaking, as well as about tech company behavior and model security.
Introduction: Purpose and Methods
The purpose of pre-release testing of Large Language Models (LLMs) in a national security context is to ensure they cannot be used to provide instructions for specific tasks, such as the creation of bioweapons or nuclear devices. Given that LLMs can exhibit behaviors that are not always transparent, even to their creators, testing could be performed to confirm they don't disclose these types of sensitive and dangerous information.
But this statement of purpose elides a big question: what’s the threat model? That is, what assumptions are we making about LLM vulnerabilities, methods through which these vulnerabilities may be identified and disseminated, and the robustness of ongoing surveillance mechanisms on the part of tech companies once these models are in use?
The answer to these questions should shape the approach to model testing. Specifically, whether an emphasis on black-box testing is adequate, or if a deeper evaluation via white-box testing is necessary. 'Black-box testing' means evaluating the system with only the same access as a normal user, while 'white-box testing' involves privileged access into the model internals. In white-box testing, testers have access to additional types of methods, like analyzing model parameters or training data, and can therefore evaluate it more comprehensively.
This question of testing methods boils down to whether we expect there to be substantial information that black-box testing methods will not elicit from an LLM, but that future users may extract. Such extraction could arise from novel black-box techniques or through the model’s theft. Theft would enable the model to be operated without safeguards, or for it to be fine-tuned, or adjusted to make it more responsive to certain types of queries that it had previously been trained to not answer.
The Jailbreaking Approach
"Jailbreaking" is a term used for crafting prompts that lead Large Language Models (LLMs) to ignore their built-in restrictions and provide answers they would normally withhold. These restrictions can part of the model's training, preventing it from responding to specific types of queries. Alternatively, they might be external safeguards that evaluate the prompts given to the model or the answers it produces. Jailbreaking attempts to deceive the model into giving prohibited responses.
Numerous efforts using a variety of different methods have successfully 'jailbroken' LLMs. These methods include asking the model to respond as a particular character, appending nonsensical adversarial strings to a prompt, or translating prompts into languages that the model has less exposure to. Prompts using these methods have almost all been generated via black-box techniques, although there has been some work on generating adversarial strings using the internal model parameters of open-source models.
One framework for thinking about pre-release testing is as a continuation of this effort, where testers will probe for unaddressed vulnerabilities and then analyze the outputs produced by the model when subjected to these prompts. That a model can be jailbroken isn’t in itself a problem in the context of this type of testing - the problem arises if the model provides accurate and dangerous information, such as instructions for creating bioweapons or nuclear devices.
In the following scenarios, a jailbreaking-focused testing effort would be sufficient for assessing LLMs.
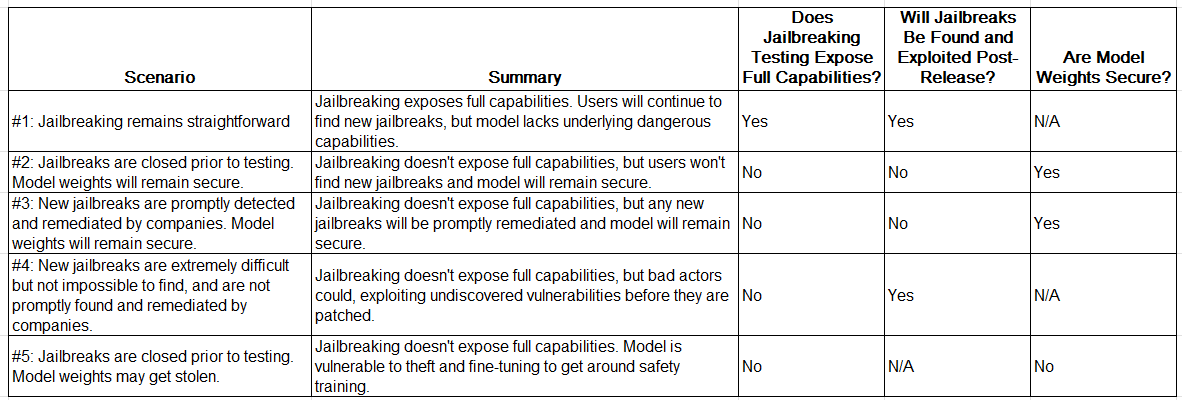
Scenario #1: Jailbreaking remains straightforward. If LLMs are built in a way that inherently allows for the ongoing discovery of new jailbreaks, with defenses being patches rather than comprehensive fixes, we can expect that testers will succeed in finding jailbreaks. If this is the case, testers will be able to perform meaningful evaluations of the model's capabilities via jailbreaking: that is, they will be able to use jailbreaking to get LLMs to answer questions about dangerous tasks to the best of their capabilities. This is the clearest scenario for the utility of jailbreaking-focused pre-release testing.
Scenario #2: Jailbreaks are closed prior to testing. Model weights will remain secure. Alternatively, perhaps the seeming infinity and peculiarity of jailbreaks is only because we’re in the early stages of understanding LLMs. In this scenario, jailbreaks will be identified and closed prior to model testing. Testers will not discover new jailbreaks or assess the full capabilities of the model – but neither will malicious actors after the model is released. For this to hold, model weights, or the underlying model parameters which determine its output, must remain secure. This means that bad actors cannot access the model and fine-tune it for increased compliance with user questions, or operate it without other safeguards. Here, testing might exist as a way of spurring companies to address vulnerabilities prior to external testing.
Scenario #3: New jailbreaks are promptly detected and remediated by companies. Model weights will remain secure. In this scenario, testers also cannot test underlying model capabilities. But should any jailbreaks remain undetected during testing, companies will promptly address these vulnerabilities post-release through monitoring of model interactions and of the overall conversations on jailbreaking. For instance, if emerging jailbreaks are typically flagged by ethical security researchers who responsibly disclose them, allowing for swift resolution, the necessity for testers to find these first diminishes. Like with the previous threat model, model weights must remain secure so that bad actors cannot access and fine-tune the model. In this threat model, testing plays a smaller role because future jailbreaks will be closed quickly and underlying model capabilities will not be accessed.
The Capabilities Approach
However, under a different set of assumptions about threat models, it becomes more important to not just engage in jailbreaking but to do a wider set of capabilities assessment, relying on white-box methods. This capabilities testing aims to evaluate the full potential of what a model is capable of and what bad actors might induce it to do.
Under the following scenarios, jailbreaking is inadequate for assessing whether models may provide instructions on the tasks of interest in the future:
Scenario #4: New jailbreaks are extremely difficult but not impossible to find, and are not promptly found and remediated by companies. This is similar to Scenario #3, in that we don’t anticipate testers will uncover the full capabilities of models via jailbreaking. However, unlike in that scenario, jailbreaking is actually possible, and we do expect bad actors to find and exploit jailbreaks before companies can detect and patch the vulnerabilities. This could be due to highly-capable bad actors discovering novel jailbreaks themselves, the lack of monitoring of model inputs and outputs on the part of companies, or the inherent difficulty of monitoring for jailbreaks.
Scenario #5: Jailbreaks are closed prior to testing. Model weights may get stolen. Like in Scenario #4, in this scenario testers won’t uncover the full capabilities of models via jailbreaking. However, here we anticipate that model weights, or the model parameters which determine the models behavior, may get stolen. This could happen within an Advanced Persistent Threats (APT) scenario with highly skilled and well-funded bad actors (such as state-sponsored hackers) who can launch sophisticated, prolonged attacks, or via insider threat. Once they steal it, they will be able to fine-tune it for increased willingness to answer questions and access its full capabilities. In this scenario, relying solely on jailbreaking will not expose the underlying model capabilities which bad actors could access.
In either of these scenarios, testing to verify that models won’t be able to provide users with classified or highly-dangerous material would need to go beyond jailbreaking into a deeper assessment of underlying model capabilities. This testing could include fine-tuning the models to bypass their training, and also potentially assessing the training materials that the model was exposed to.
Summary info about each model is below:
Summary of Threat Scenarios
Further Study on Different Threat Models
Given how new these models are, there’s unlikely to be definitive evidence for any of these threat scenarios. However, there are areas where limited evidence could be found.
Jailbreak emergence: Particularly with collaboration from companies which own existing LLMs, it might be possible to track the emergence of jailbreaking methods in order to differentiate between different models of discovery and usage. For instance, to what extent are jailbreaks being discovered by security researchers who inform companies prior to those jailbreaks showing up on the internet, or being used in a widespread way? Is there evidence yet of model vulnerability probing by organized bad actors?
Ease of closing vulnerabilities: There’s existing research on the extent to which jailbreaks can be mitigated without making models broadly less-useful. For instance, adversarial strings may be able to be detected via a combination of perplexity and token length, or how unexpected the sequence of words in the prompt is and its length. Attacks in other languages could potentially be detected via translating all prompts to languages that the model has a lot of exposure to. A deep dive into this - and, again, companies are likely to have internal research on these topics – could potentially begin to answer questions about to what extent model defenses close vulnerabilities in a systematic sense vs. just patch them.
Conclusion
The appropriate approach to pre-release testing of large language models depends on the anticipated threat model. If it remains straightforward to find new vulnerabilities via black box testing, then testing focused on discovering new jailbreaks and using those to assess capabilities may be sufficient for assessing underlying model capabilities. Alternatively, if model weights are secure and new jailbreaks are either impossible to find or will be quickly discovered by post-release monitoring, then testing may not be able to fully-assess model capabilities, but doing this may be unnecessary, as full model capabilities will also not be available to bad actors.
However, if theft of model weights is a concern, or if jailbreaking vulnerabilities are not easily discovered through testing, but may be discoverable by future bad actors before they can be closed, then more extensive assessment of underlying model capabilities is necessary for assessment of these models.
Further research on the emergence of jailbreaks over time and the robustness of defenses could help determine which scenarios are most likely. Ultimately, if testing occurs, the goal should be testing that is appropriate for the anticipated risks.
You should reach out to Ycombinator and pitch a startup that provides a "Jailbreak detection and prevention for LLM models." Sort of like the Palo Alto firewalls that inspect application traffic for threats.