
But Is It Cake?
Binary Classification Models and Generalization
There’s this great show about binary classification models on Netflix.
I’m referring, of course, to “Is It Cake?”
On the show, bakers create hyper-realistic cakes, or cakes that look like all kinds of objects – plastic elephants, suitcases, rollerblades – and then are awarded money if they can fool judges into thinking that their cake is the real object and not the cake.

It’s also a good way to illustrate the concepts of model performance and generalization.
Your brain has a model of what cake is, meaning that if presented with something in the normal course of your life, you can accurately answer the question, "Is it cake?" just by looking. You have a basically perfect cake classification model, as represented below.
Everything is in green, meaning that the "true" value — cake or not cake — is the same as the "labeled" value, or what your model predicted it would be. You accurately label each kind of cake as cake, and each not-cake item as not-cake. There are only "true positives" — cakes you correctly labeled as cake — and "true negatives", or non-cakes that you correctly labeled as non-cakes.

However! If you use that model on "Is It Cake?", it will fail, because the whole point is that ANYTHING COULD BE CAKE. The visual cues that worked before— the features that your model was based on — don't work anymore. When you 'trained' your model through years of observing cake and non-cake objects, it didn't include objects that were specifically designed to fool you, so it failed to generalize on this new dataset.
You can see that in the table below: your normal cake classification model says that NOTHING in that show is cake, because none of the cakes created look like normal cakes.
And it's correct some of the time – because some of the non-cake-looking objects really aren't cakes! But it misses the cakes shaped like chairs, steaks, shoes, etc. Now you have exclusively "true negatives" – the green objects that are actually just normal objects – but also "false negatives", where you're labeling cake as not-cake.
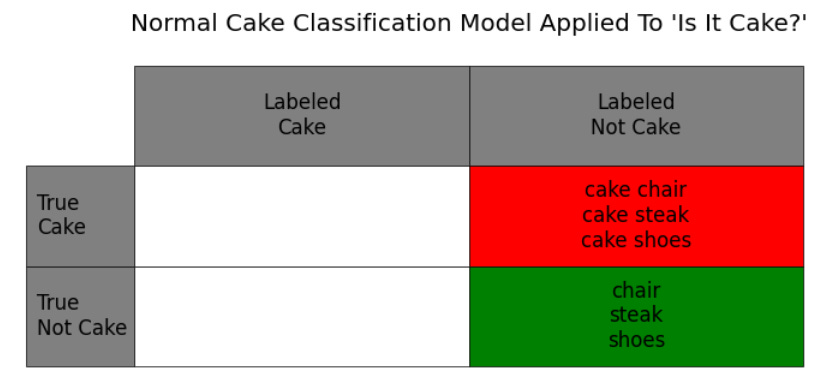
If you watch the show, you can see the contestants and judges coming up with a whole new system, or model, for detecting cake based on small details. If they were to do a perfect job of this — to notice the details that separate shoes that are actually shoes from shoes that are cake — then you'd go back to a table that looks like the first one, where you're able to perfectly identify cake and not-cake.
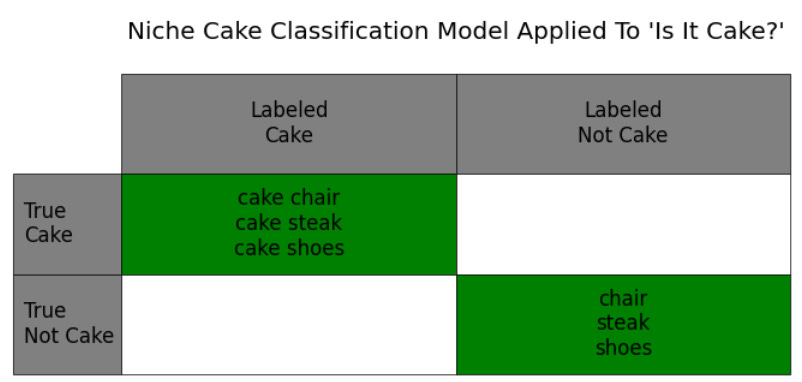
But finally, what if you tried to use that model again in the real world? What if you looked for objects that were just a little off — a little odd-looking, that maybe sat a little wrong, or had a texture that didn't seem quite right? If you were to do that, your new model would not actually be a better model in general for the real world. If you walk through life slicing or biting into things that, on the show, would probably be cake, you will be disappointed almost 100% of the time. It's not cake!
You can see that in the table below, where there's now a new category of "false positives," or non-cake objects that are incorrectly labeled as cake.
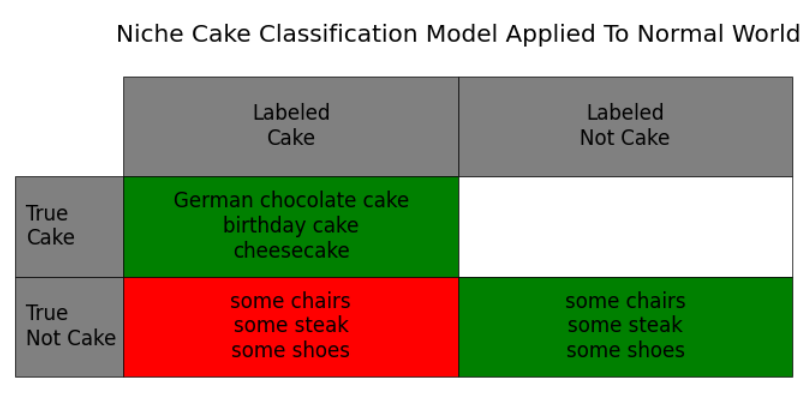
Why is that? Your initial model was a great model for everyday life. Your new model is a better model for this show. "Model performance" isn't just about the model in some abstract, divorced-from-reality sense; it's about the model PLUS the context, or the data you're applying it to.
In the show, the chair might be cake. Disappointingly, in real life, it is not!
I’m giving a talk in New York as part of the New York R (and friends!) Conference on May 16-17th. I’ll be talking about automating tests for generative AI tools. More info and tickets here.
Had a kid who was into that show. Nice example to illustrate your point!